
오늘은 네이버 웹문서 검색 api를 가져와, '인공지능'에 대한 웹검색 / 뉴스 / 블로그에대 분석해보고 시각화해보겠습니다.
import os
import sys
import urllib.request
import pandas as pd
import json
import re
import urllib.request
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
plt.style.use('seaborn-white')
client_id = '#########' # 개인 client id
client_secret = '#########' # 개인 client secret
query = urllib.parse.quote(input('검색 질의: '))
idx = 0
display = 100
start = 1
end = 1000
web_df = pd.DataFrame(columns=('Title', 'Link', 'Description'))
for start_idx in range(start, end, display):
url = 'https://openapi.naver.com/v1/search/webkr?query=' + query + '\\'
'&display=' + str(display) + '&start=' + str(start_idx)
request = urllib.request.Request(url)
request.add_header('X-Naver-Client-Id', client_id)
request.add_header('X-Naver-Client-Secret', client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode == 200):
response_body = response.read()
response_dict = json.loads(response_body.decode('utf-8'))
items = response_dict['items']
for item_idx in range(0, len(items)):
remove_tag = re.compile('<.*?>')
title = re.sub(remove_tag, '', items[item_idx]['title'])
link = items[item_idx]['link']
description = re.sub(remove_tag, '', items[item_idx]['description'])
web_df.loc[idx] = [title, link, description]
idx += 1
else:
print('Error Code: ' + rescode)
web_df먼저 네이버 api를 이용하려면 각자 네이버 개발자 센터에 들어가서 개인 client_id와 cilent_secret을 발급 받습니다.
위의 코드를 실행시키면 '검색 질의: '라는 input으로 우리가 검색하고자 하는 '인공지능' 키워드를 적어줍니다.
먼저 인공지능에 대한 웹검색 api를 이용해 보겠습니다.
각 Title / Link / Description 데이터 프레임을 만들고 거기에 넣어주겠습니다.

이런식으로 데이터 프레임을 잘 가져온걸 볼 수 있습니다.
web = []
for d in web_df.Description:
web.append(d)
print(web[:5])
저희는 'Descirption'에서 insight가 많을 거 같아, 분석을 위해 'Descirption' 값만 따로 빼주겠습니다.
# 불용어 예제 : 인공지능 인공 지능 분야 수 것 등 기반 일 년 말 문 월 이 명 깨 개 중 범 부 딥 빅 책 분 봉 차 나 대 전 억 대 형 선 사 폼 원 번
stop_words = '인공지능 인공 지능 분야 수 것 등 기반 일 년 말 문 월 이 명 깨 개 중 범 부 딥 빅 책 분 봉 차 나 대 전 억 대 형 선 사 폼 원 번'
stop_words = stop_words.split(' ')
print(stop_words)
다음으로 형태소 분석을 이용한 명사 추출을 해볼건데, 사전에 미리 정의한 불용어 사전에 해당 값을 넣어줍니다. 인공지능이란 단어는 애초에 인공지능이라는 키워드를 검색했기 때문에 명사 비율이 많을 것 입니다. 오히려 분석에 방해가 될거 같아, 불용어 사전에 추가합니다.
from konlpy.tag import Mecab
tagger = Mecab(r'C:\mecab\mecab-ko-dic')
web_nouns = []
for w in web:
for noun in tagger.nouns(w):
if noun not in stop_words:
web_nouns.append(noun)
web_nouns[:10]
저희는 Mecab()이라는 형태소 분석기를 이용해 따로 명사를 추출해주겠습니다.
# 단어 빈도수 측정
from collections import Counter
web_nouns_counter = Counter(web_nouns)
top_web_nouns = dict(web_nouns_counter.most_common(100))
top_web_nouns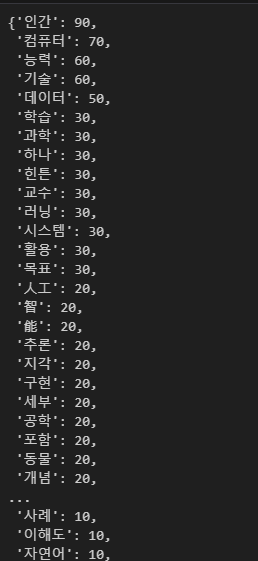
다음으로, Counter 라이브러리를 이용하여 단어 빈도수 측정을 해보겠습니다.
역시 인공지능이니만큼, 인간, 컴퓨터, 능력, 기술, 데이터... 순으로 많이 키워드가 분포되어있는 결과를 보실 수 있습니다.
import matplotlib.font_manager as fm
font_list = fm.findSystemFonts(fontpaths = None, fontext = 'ttf')
from matplotlib import rc
font_path = 'C:\\Windows\\Fonts\\Hancom Gothic Bold.ttf'
font = fm.FontProperties(fname=font_path).get_name()
rc('font', family=font)
# 단어 빈도 시각화
import numpy as np
plt.rcParams['font.size'] = 12
y_pos = np.arange(len(top_web_nouns))
plt.figure(figsize=(12,24))
plt.barh(y_pos, top_web_nouns.values())
plt.title('Word Count')
plt.yticks(y_pos, top_web_nouns.keys())
plt.show()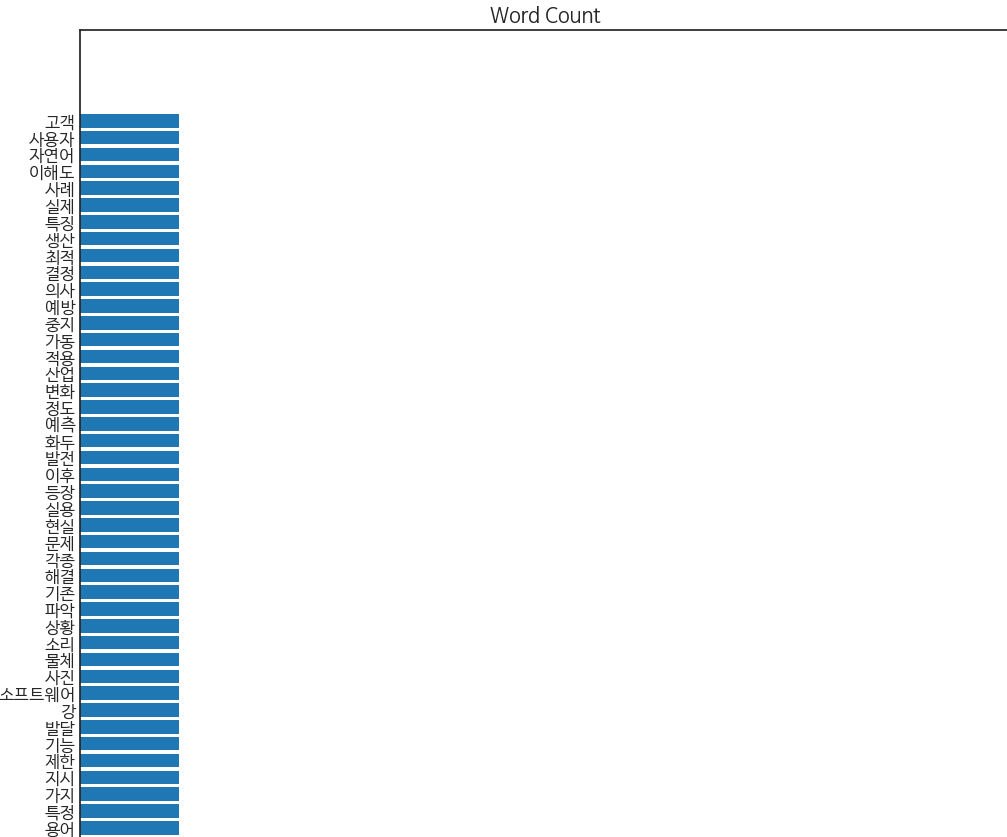
직관성을 위해 단어빈도를 시각화 해보았습니다.
# 트리맵 시각화
import squarify
norm = mpl.colors.Normalize(vmin=min(top_web_nouns.values()),
vmax=max(top_web_nouns.values()))
colors = [mpl.cm.Reds(norm(value)) for value in top_web_nouns.values()]
squarify.plot(label=top_web_nouns.keys(),
sizes=top_web_nouns.values(),
color=colors)

저는 이 둘이 생각보다 눈으로 확 들어오지 않는 것 같아, 워드 클라우드 시각화를 이용해보겠습니다.
# 인공지능 웹문서에 나온 키워드 워드클라우드 시각화
from wordcloud import WordCloud
wc = WordCloud(background_color = 'white', font_path='C:\\Windows\\Fonts\\Hancom Gothic Bold.ttf')
wc.generate_from_frequencies(top_web_nouns)
figure = plt.figure(figsize=(14, 14))
ax = figure.add_subplot(1, 1, 1)
ax.axis('off')
ax.imshow(wc)
plt.show()
도출된 결과입니다. 확실히 눈에 보이는 것은 예상할 수 있듯이, 컴퓨터, 인간, 데이터, 기술, 능력 이런 키워드가 많이 분포되어 있는 것을 확인 할 수 있습니다.
아무래도 웹검색은 단어 사전도 있고, 어학 사전, 개념을 알려주는 검색 결과가 많다보니, 인공지능에 관해, 예측이 평이한 수준으로 insight가 도출되었습니다.
그래서 요즘 트렌드를 반영하는 뉴스로 키워드 분석을 진행해보도록 하겠습니다.
코드는 비슷하게 하되, 네이버 api 별 메뉴얼로 컬럼 조정과 url을 조정하면 실행이 됩니다.
# 네이버 뉴스 키워드 분석
import os
import sys
import urllib.request
import pandas as pd
import numpy as np
import json
import re
import urllib.request
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
plt.style.use('seaborn-white')
client_id = '#########' # 개인 client id
client_secret = '#########' # 개인 client secret
query = urllib.parse.quote(input('검색 질의: '))
idx = 0
display = 100
start = 1
end = 1000
sort = 'sim'
news_df = pd.DataFrame(columns=('Title', 'Original Link', 'Link', 'Description', 'Publication Date'))
for start_idx in range(start, end, display):
url = 'https://openapi.naver.com/v1/search/news?query=' + query + '\\'
'&display=' + str(display) + '&start=' + str(start_idx) + '&sort=' + sort
request = urllib.request.Request(url)
request.add_header('X-Naver-Client-Id', client_id)
request.add_header('X-Naver-Client-Secret', client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode == 200):
response_body = response.read()
response_dict = json.loads(response_body.decode('utf-8'))
items = response_dict['items']
for item_idx in range(0, len(items)):
remove_tag = re.compile('<.*?>')
title = re.sub(remove_tag, '', items[item_idx]['title'])
original_link = items[item_idx]['originallink']
link = items[item_idx]['link']
description = re.sub(remove_tag, '', items[item_idx]['description'])
pub_date = items[item_idx]['pubDate']
news_df.loc[idx] = [title, original_link, link, description, pub_date]
idx += 1
else:
print('Error Code: ' + rescode)
news_df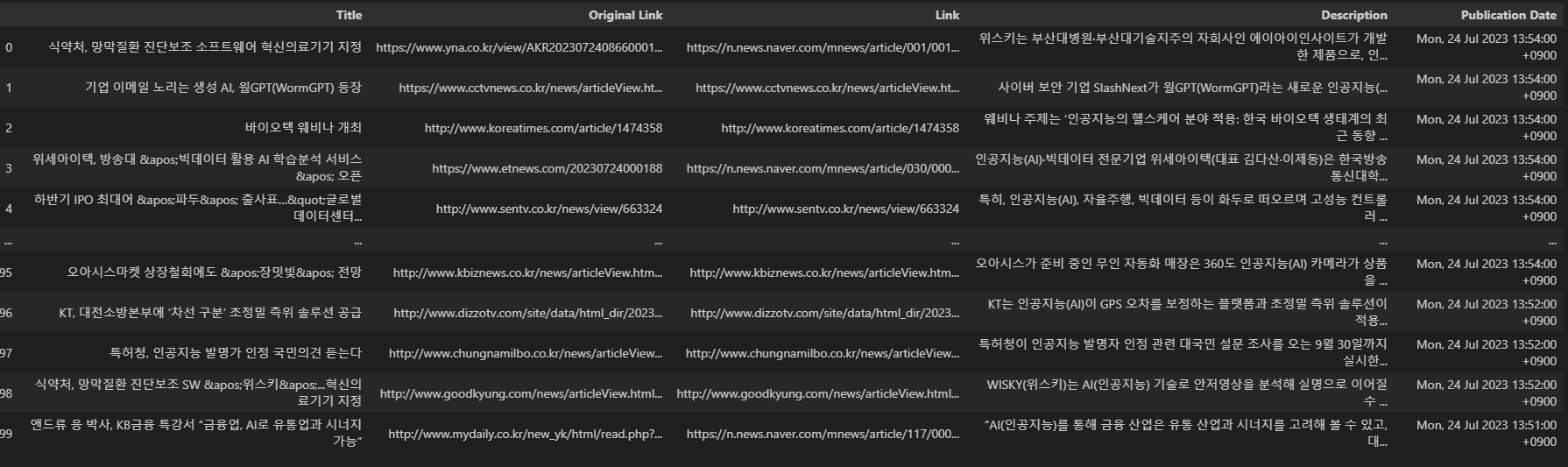
저는 이 컬럼 중에서도 아무래도 뉴스이다 보니, Title에 요약과 키워드를 잘 반영할 것 같아 Title을 따로 분석을 해보겠습니다.
위에 키워드 분석과 동일하게 코드를 진행해보면,

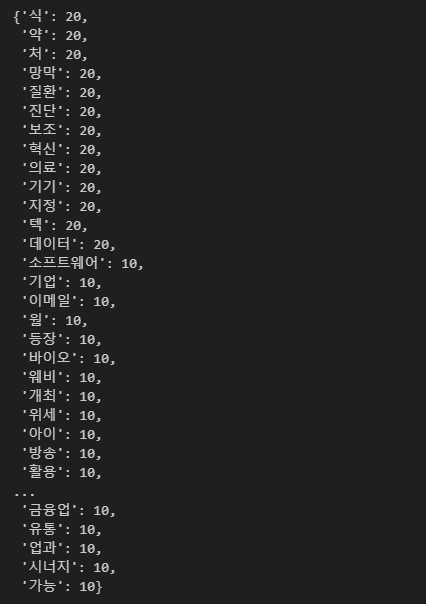
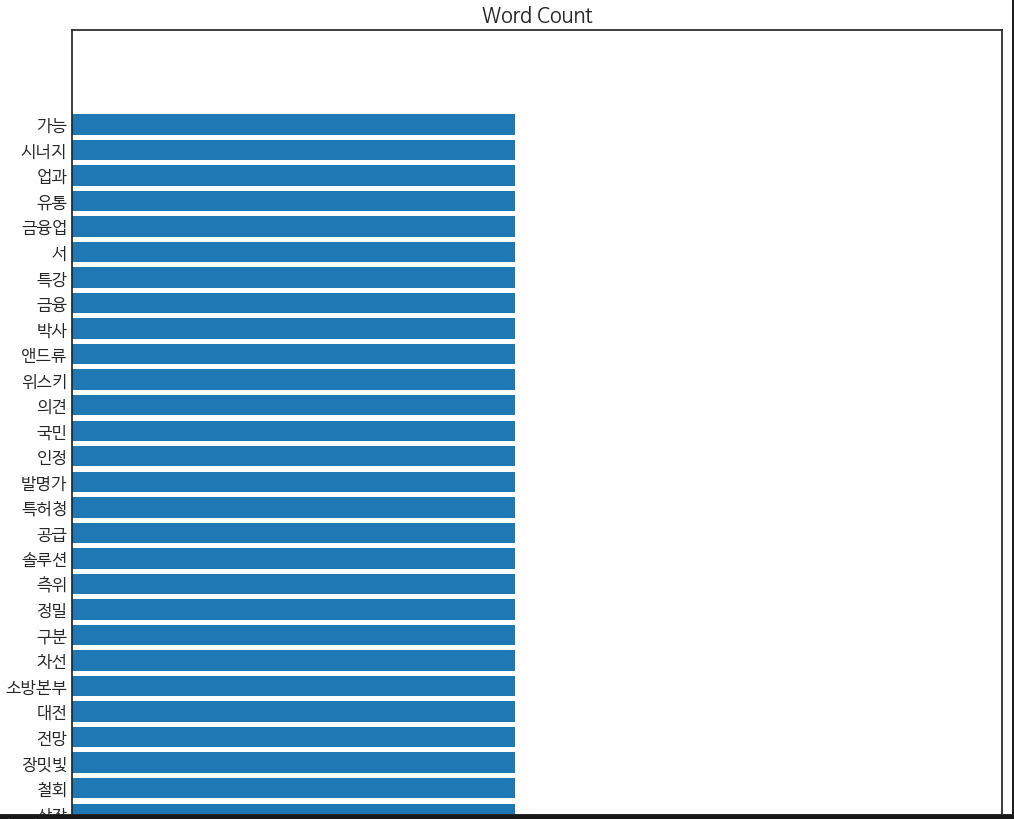

정도가 될것 같습니다.
최종으로 인공지능 뉴스에 나온 키워드를 워드클라우드로 시각화 해보면,

로 도출이 됩니다.
아마 '인공지능과 의료쪽으로 식약처와 망막 질환 진단을 접목시키는 혁신적인 솔루션을 계획한다'고 분석될 것 같습니다.
마지막으로 네이버는 블로그에도 이슈들을 처리하고 리뷰하는 것이 발달이 되어있어, 블로그 '인공지능' 키워드도 분석해보겠습니다.
코드는 비슷하게, 네이버 블로그 api 메뉴얼에 맞게 컬럼 조정과 url을 조정하겠습니다.
client_id = '#########' # 개인 client id
client_secret = '#########' # 개인 client secret
query = urllib.parse.quote(input('검색 질의: '))
idx = 0
display = 100
start = 1
end = 1000
sort = 'sim'
blog_df = pd.DataFrame(columns=('Title', 'Link', 'Description', 'Blogger Name', 'Blogger Link'))
for start_idx in range(start, end, display):
url = 'https://openapi.naver.com/v1/search/blog?query=' + query + '\\'
'&display=' + str(display) + '&start=' + str(start_idx) + '&sort=' + sort
request = urllib.request.Request(url)
request.add_header('X-Naver-Client-Id', client_id)
request.add_header('X-Naver-Client-Secret', client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode == 200):
response_body = response.read()
response_dict = json.loads(response_body.decode('utf-8'))
items = response_dict['items']
for item_idx in range(0, len(items)):
remove_tag = re.compile('<.*?>')
title = re.sub(remove_tag, '', items[item_idx]['title'])
link = items[item_idx]['link']
description = re.sub(remove_tag, '', items[item_idx]['description'])
blogger_name = items[item_idx]['bloggername']
blogger_link = items[item_idx]['bloggerlink']
blog_df.loc[idx] = [title, link, description, blogger_name, blogger_link]
idx += 1
else:
print('Error Code: ' + rescode)
blog_df
블로그 데이터 프레임을 보면, 아마도 블로그 내용으로 칼럼이나, 중요한 내용들을 적어놨을 것이라고 가정하겠습니다.

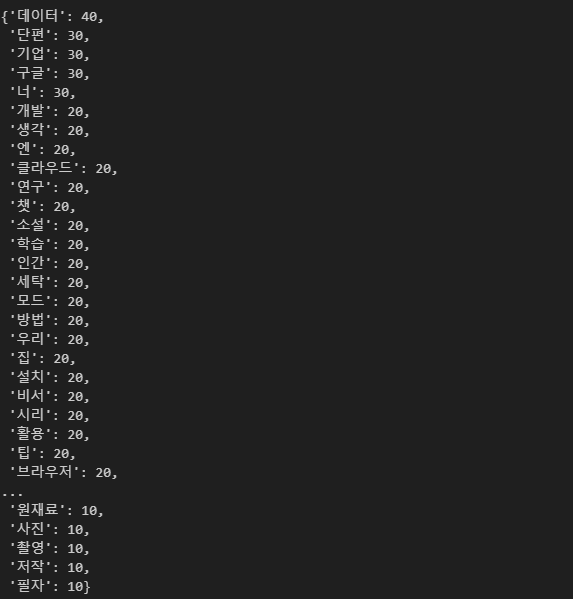
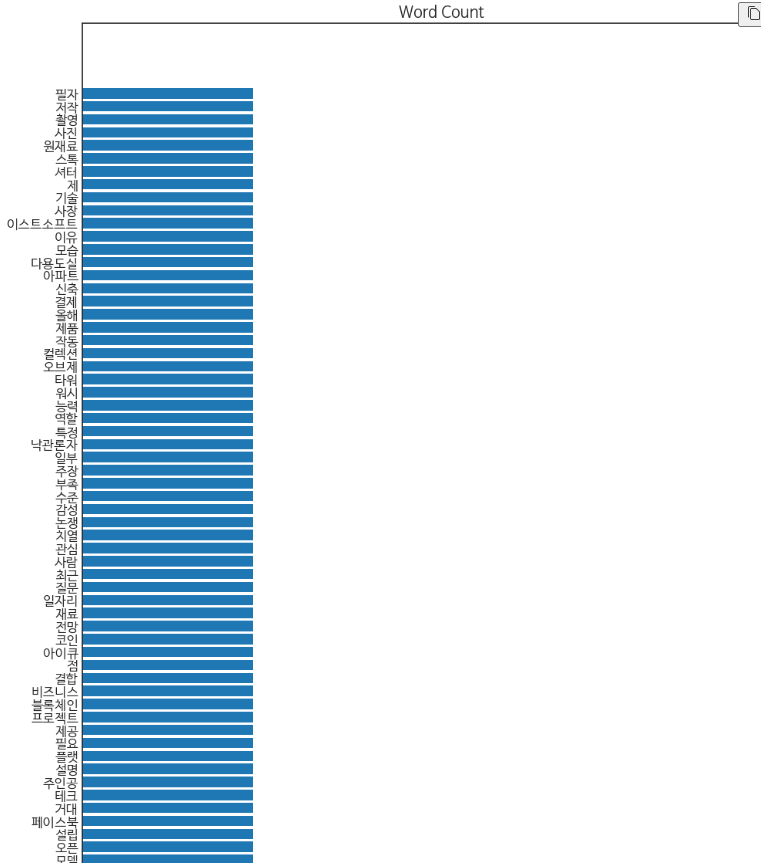
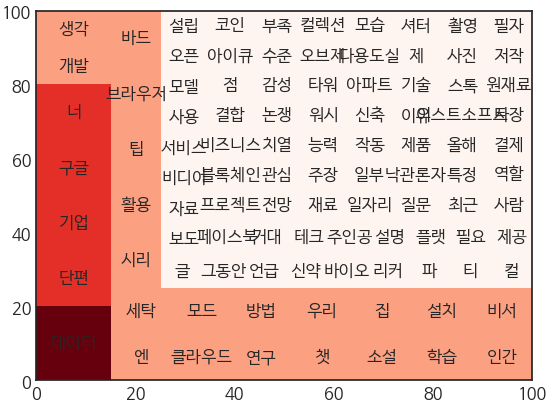
위와 동일하게 Mecab()을 이용하여 형태소 분석, 다양한 시각화를 진행하였습니다.
마지막으로 워드클라우드 시각화를 해주면,

아무래도 챗GPT열풍으로 인해, 이에 맞서 구글에서도 '바드'라는 인공지능을 오픈했습니다. 더욱더 개발이 필요한 분야이기도 하구요. 아마 대화형 인공지능이 요즘 대세이기도 하고 그와 관련된 구글, 여러 생각 방면으로 개발되고 있다. 정도로 유추할 수 있을거 같습니다.
이번 포스팅에서는 네이버 api를 이용하여 웹검색 / 뉴스 / 블로그 별로 분석을 진행해보았는데, 같은 단어라도 다양한 결과가 나왔듯이 다른 분야에 대해서도 다양한 시각 분석을 하는 것이 필요할 것 같습니다.
'Data Analysis > Natural Language Processing(NLP)' 카테고리의 다른 글
| 양질의 데이터 확보하기 (0) | 2023.07.05 |
|---|---|
| KoNLPy 설치하기(Windows) (0) | 2023.07.05 |
| KoNLPy 설치하기(M1) (0) | 2023.07.05 |
| 형태소 분석 (0) | 2023.07.05 |
| py-hanspell 설치하기 (0) | 2023.07.05 |