
-
Name Gender DAG 개선하기, 구글 Colab으로 만든 DAG를 Airflow로 4가지 버전으로 만들면서 Airflow의 기능을 이해해 보자
-
Python 코드를 Airflow로 포팅하기
-
NameGenderCSVtoRedshift.py 개선하기 #1
-
NameGenderCSVtoRedshift.py 개선하기 #2
-
NameGenderCSVtoRedshift.py 개선하기 #3
-
Connections and Variables
-
Web UI
-
Redshift Connection 설정 (Data Warehouse)
-
Airflow Web UI after the Successful Installation
Name Gender DAG 개선하기, 구글 Colab으로 만든 DAG를 Airflow로 4가지 버전으로 만들면서 Airflow의 기능을 이해해 보자
Python 코드를 Airflow로 포팅하기
NameGenderCSVtoRedshift.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
import requests
import logging
import psycopg2
def get_Redshift_connection():
host = "#####.redshift.amazonaws.com"
user = "#####" # 본인 ID 사용
password = "#####" # 본인 Password 사용
port = 5439
dbname = "dev"
conn = psycopg2.connect(f"dbname={dbname} user={user} host={host} password={password} port={port}")
conn.set_session(autocommit=True)
return conn.cursor()
def extract(url):
logging.info("Extract started")
f = requests.get(url)
logging.info("Extract done")
return (f.text)
def transform(text):
logging.info("Transform started")
lines = text.strip().split("\n")[1:] # 첫 번째 라인을 제외하고 처리
records = []
for l in lines:
(name, gender) = l.split(",") # l = "Keeyong,M" -> [ 'keeyong', 'M' ]
records.append([name, gender])
logging.info("Transform ended")
return records
def load(records):
logging.info("load started")
"""
records = [
[ "Keeyong", "M" ],
[ "Claire", "F" ],
...
]
"""
schema = "keeyong"
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
cur = get_Redshift_connection()
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema}.name_gender;")
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = f"INSERT INTO {schema}.name_gender VALUES ('{name}', '{gender}')"
cur.execute(sql)
cur.execute("COMMIT;") # cur.execute("END;")
except (Exception, psycopg2.DatabaseError) as error:
print(error)
cur.execute("ROLLBACK;")
raise
logging.info("load done")
def etl():
link = "https://s3-geospatial.s3-us-west-2.amazonaws.com/name_gender.csv"
data = extract(link)
lines = transform(data)
load(lines)
dag_second_assignment = DAG(
dag_id = 'name_gender',
catchup = False,
start_date = datetime(2023,4,6), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *') # 적당히 조절
task = PythonOperator(
task_id = 'perform_etl',
python_callable = etl,
dag = dag_second_assignment)1. 헤더가 레코드로 추가되는 문제 해결하기
2. Idempotent하게 잡을 만들기(멱등성)
a. 여러 번 실행해도 동일한 결과가 나오게 만들기
b. 매번 새로 모든 데이터를 읽어오는 잡이라고 가정하고 구현할 것
NameGenderCSVtoRedshift.py 개선하기 #1
NameGenderCSVtoRedshift_v2.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.models import Variable
from datetime import datetime
from datetime import timedelta
import requests
import logging
import psycopg2
def get_Redshift_connection():
return conn.cursor()
def extract(url):
return (f.text)
def transform(text):
return records
def load(records):
logging.info("load done")
def etl(**context):
link = context["params"]["url"]
# task 자체에 대한 정보 (일부는 DAG의 정보가 되기도 함)를 읽고 싶다면 context['task_instance'] 혹은 context['ti']를 통해 가능
# https://airflow.readthedocs.io/en/latest/_api/airflow/models/taskinstance/index.html#airflow.models.TaskInstance
task_instance = context['task_instance']
execution_date = context['execution_date']
logging.info(execution_date)
data = extract(link)
lines = transform(data)
load(lines)
dag = DAG(
dag_id = 'name_gender_v2',
start_date = datetime(2023,4,6), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *', # 적당히 조절
catchup = False,
max_active_runs = 1,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
task = PythonOperator(
task_id = 'perform_etl',
python_callable = etl,
params = {
'url': "https://s3-geospatial.s3-us-west-2.amazonaws.com/name_gender.csv"
},
dag = dag)● params를 통해 변수 넘기기
● execution_date 얻어내기
● “delete from” vs. “truncate”
○ DELETE FROM raw_data.name_gender; -- WHERE 사용 가능
○ TRUNCATE raw_data.name_gender;
NameGenderCSVtoRedshift.py 개선하기 #2
NameGenderCSVtoRedshift_v3.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.models import Variable
from datetime import datetime
from datetime import timedelta
import requests
import logging
import psycopg2
def get_Redshift_connection():
return conn.cursor()
def extract(**context):
return (f.text)
def transform(**context):
return records
def load(**context):
logging.info("load done")
dag = DAG(
dag_id = 'name_gender_v3',
start_date = datetime(2023,4,6), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *', # 적당히 조절
catchup = False,
max_active_runs = 1,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
extract = PythonOperator(
task_id = 'extract',
python_callable = extract,
params = {
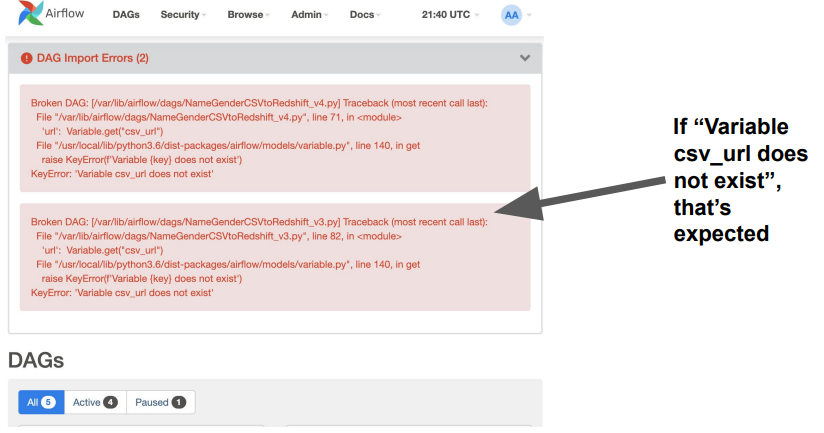
'url': Variable.get("csv_url")
},
dag = dag)
transform = PythonOperator(
task_id = 'transform',
python_callable = transform,
params = {
},
dag = dag)
load = PythonOperator(
task_id = 'load',
python_callable = load,
params = {
'schema': 'keeyong',
'table': 'name_gender'
},
dag = dag)
extract >> transform >> load● Xcom 객체를 사용해서 세 개의 task로 나누기
● Redshift의 스키마와 테이블 이름을 params로 넘기기
NameGenderCSVtoRedshift.py 개선하기 #3
NameGenderCSVtoRedshift_v4.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.models import Variable
from airflow.providers.postgres.hooks.postgres import PostgresHook
from datetime import datetime
from datetime import timedelta
# from plugins import slack
import requests
import logging
import psycopg2
def get_Redshift_connection(autocommit=True):
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
conn = hook.get_conn()
conn.autocommit = autocommit
return conn.cursor()
def extract(**context):
link = context["params"]["url"]
task_instance = context['task_instance']
execution_date = context['execution_date']
logging.info(execution_date)
f = requests.get(link)
return (f.text)
def transform(**context):
logging.info("Transform started")
text = context["task_instance"].xcom_pull(key="return_value", task_ids="extract")
if text is None:
print("++++++++++++++++++++++++++++++")
lines = text.strip().split("\n")[1:] # 첫 번째 라인을 제외하고 처리
records = []
for l in lines:
(name, gender) = l.split(",") # l = "Keeyong,M" -> [ 'keeyong', 'M' ]
records.append([name, gender])
logging.info("Transform ended")
return records
def load(**context):
logging.info("load started")
schema = context["params"]["schema"]
table = context["params"]["table"]
records = context["task_instance"].xcom_pull(key="return_value", task_ids="transform")
"""
records = [
[ "Keeyong", "M" ],
[ "Claire", "F" ],
...
]
"""
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
cur = get_Redshift_connection()
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema}.name_gender;")
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = f"IINSERT INTO {schema}.name_gender VALUES ('{name}', '{gender}')"
cur.execute(sql)
cur.execute("COMMIT;") # cur.execute("END;")
except (Exception, psycopg2.DatabaseError) as error:
print("Error Msg", error)
cur.execute("ROLLBACK;")
raise
logging.info("load done")
dag = DAG(
dag_id = 'name_gender_v4',
start_date = datetime(2023,4,6), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *', # 적당히 조절
max_active_runs = 1,
catchup = False,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
# 'on_failure_callback': slack.on_failure_callback,
}
)
extract = PythonOperator(
task_id = 'extract',
python_callable = extract,
params = {
'url': Variable.get("csv_url")
},
dag = dag)
transform = PythonOperator(
task_id = 'transform',
python_callable = transform,
params = {
},
dag = dag)
load = PythonOperator(
task_id = 'load',
python_callable = load,
params = {
'schema': '#####', ## 자신의 스키마로 변경
'table': 'name_gender'
},
dag = dag)
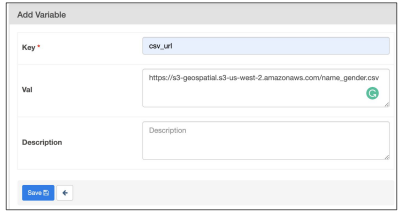
extract >> transform >> load● Variable를 이용해 CSV parameter 넘기기
● csv_url: ○ https://s3-geospatial.s3-us-west-2.amazonaws .com/name_gender.csv
○ 값을 암호화하려면 (*****)
Connections and Variables
● Connections
○ This is used to store some connection related info such as hostname, port number, and access credential
(호스트 이름, 포트 번호, 액세스 자격 증명 등 일부 연결 관련 정보를 저장하는 데 사용)
○ Postgres connection or Redshift connection info can be stored here
(Postgres 연결 또는 Redshift 연결 정보를 저장)
● Variables
○ Used to store API keys or some configuration info (API 키 또는 일부 구성 정보를 저장하는 데 사용)
○ Use “access” or “secret” in the name if you want its value to be encrypted (값을 암호화하려면 이름에 "access" 또는 "secret"를 사용)
○ We will practice this(우리는 이걸 연습해볼 것이다.)
Web UI
Airflow Connections
Airflow Variables
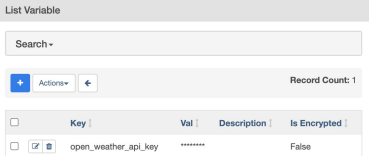
Redshift Connection 설정 (Data Warehouse)
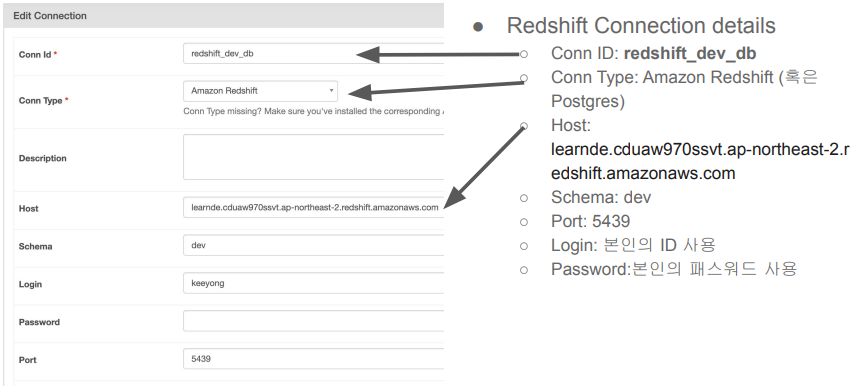
Airflow Web UI after the Successful Installation
'Data Engineering > 실리콘밸리에서 날아온 데이터 엔지니어링 스타터 키트' 카테고리의 다른 글
| [5주차] Airflow Deepdive 2 - API를 사용해서 DAG 만들어보기 (0) | 2023.09.14 |
|---|---|
| [4주차] Assignment (0) | 2023.09.10 |
| [4주차] Airflow Deepdive - Airflow로 데이터 파이프라인 만들기 (1) (0) | 2023.09.05 |
| [4주차] 데이터베이스 트랜잭션 (0) | 2023.09.05 |
| [3주차] Assignment (0) | 2023.08.31 |
Name Gender DAG 개선하기, 구글 Colab으로 만든 DAG를 Airflow로 4가지 버전으로 만들면서 Airflow의 기능을 이해해 보자
Python 코드를 Airflow로 포팅하기
NameGenderCSVtoRedshift.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
import requests
import logging
import psycopg2
def get_Redshift_connection():
host = "#####.redshift.amazonaws.com"
user = "#####" # 본인 ID 사용
password = "#####" # 본인 Password 사용
port = 5439
dbname = "dev"
conn = psycopg2.connect(f"dbname={dbname} user={user} host={host} password={password} port={port}")
conn.set_session(autocommit=True)
return conn.cursor()
def extract(url):
logging.info("Extract started")
f = requests.get(url)
logging.info("Extract done")
return (f.text)
def transform(text):
logging.info("Transform started")
lines = text.strip().split("\n")[1:] # 첫 번째 라인을 제외하고 처리
records = []
for l in lines:
(name, gender) = l.split(",") # l = "Keeyong,M" -> [ 'keeyong', 'M' ]
records.append([name, gender])
logging.info("Transform ended")
return records
def load(records):
logging.info("load started")
"""
records = [
[ "Keeyong", "M" ],
[ "Claire", "F" ],
...
]
"""
schema = "keeyong"
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
cur = get_Redshift_connection()
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema}.name_gender;")
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = f"INSERT INTO {schema}.name_gender VALUES ('{name}', '{gender}')"
cur.execute(sql)
cur.execute("COMMIT;") # cur.execute("END;")
except (Exception, psycopg2.DatabaseError) as error:
print(error)
cur.execute("ROLLBACK;")
raise
logging.info("load done")
def etl():
link = "https://s3-geospatial.s3-us-west-2.amazonaws.com/name_gender.csv"
data = extract(link)
lines = transform(data)
load(lines)
dag_second_assignment = DAG(
dag_id = 'name_gender',
catchup = False,
start_date = datetime(2023,4,6), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *') # 적당히 조절
task = PythonOperator(
task_id = 'perform_etl',
python_callable = etl,
dag = dag_second_assignment)1. 헤더가 레코드로 추가되는 문제 해결하기
2. Idempotent하게 잡을 만들기(멱등성)
a. 여러 번 실행해도 동일한 결과가 나오게 만들기
b. 매번 새로 모든 데이터를 읽어오는 잡이라고 가정하고 구현할 것
NameGenderCSVtoRedshift.py 개선하기 #1
NameGenderCSVtoRedshift_v2.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.models import Variable
from datetime import datetime
from datetime import timedelta
import requests
import logging
import psycopg2
def get_Redshift_connection():
return conn.cursor()
def extract(url):
return (f.text)
def transform(text):
return records
def load(records):
logging.info("load done")
def etl(**context):
link = context["params"]["url"]
# task 자체에 대한 정보 (일부는 DAG의 정보가 되기도 함)를 읽고 싶다면 context['task_instance'] 혹은 context['ti']를 통해 가능
# https://airflow.readthedocs.io/en/latest/_api/airflow/models/taskinstance/index.html#airflow.models.TaskInstance
task_instance = context['task_instance']
execution_date = context['execution_date']
logging.info(execution_date)
data = extract(link)
lines = transform(data)
load(lines)
dag = DAG(
dag_id = 'name_gender_v2',
start_date = datetime(2023,4,6), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *', # 적당히 조절
catchup = False,
max_active_runs = 1,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
task = PythonOperator(
task_id = 'perform_etl',
python_callable = etl,
params = {
'url': "https://s3-geospatial.s3-us-west-2.amazonaws.com/name_gender.csv"
},
dag = dag)● params를 통해 변수 넘기기
● execution_date 얻어내기
● “delete from” vs. “truncate”
○ DELETE FROM raw_data.name_gender; -- WHERE 사용 가능
○ TRUNCATE raw_data.name_gender;
NameGenderCSVtoRedshift.py 개선하기 #2
NameGenderCSVtoRedshift_v3.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.models import Variable
from datetime import datetime
from datetime import timedelta
import requests
import logging
import psycopg2
def get_Redshift_connection():
return conn.cursor()
def extract(**context):
return (f.text)
def transform(**context):
return records
def load(**context):
logging.info("load done")
dag = DAG(
dag_id = 'name_gender_v3',
start_date = datetime(2023,4,6), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *', # 적당히 조절
catchup = False,
max_active_runs = 1,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
extract = PythonOperator(
task_id = 'extract',
python_callable = extract,
params = {
'url': Variable.get("csv_url")
},
dag = dag)
transform = PythonOperator(
task_id = 'transform',
python_callable = transform,
params = {
},
dag = dag)
load = PythonOperator(
task_id = 'load',
python_callable = load,
params = {
'schema': 'keeyong',
'table': 'name_gender'
},
dag = dag)
extract >> transform >> load● Xcom 객체를 사용해서 세 개의 task로 나누기
● Redshift의 스키마와 테이블 이름을 params로 넘기기
NameGenderCSVtoRedshift.py 개선하기 #3
NameGenderCSVtoRedshift_v4.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.models import Variable
from airflow.providers.postgres.hooks.postgres import PostgresHook
from datetime import datetime
from datetime import timedelta
# from plugins import slack
import requests
import logging
import psycopg2
def get_Redshift_connection(autocommit=True):
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
conn = hook.get_conn()
conn.autocommit = autocommit
return conn.cursor()
def extract(**context):
link = context["params"]["url"]
task_instance = context['task_instance']
execution_date = context['execution_date']
logging.info(execution_date)
f = requests.get(link)
return (f.text)
def transform(**context):
logging.info("Transform started")
text = context["task_instance"].xcom_pull(key="return_value", task_ids="extract")
if text is None:
print("++++++++++++++++++++++++++++++")
lines = text.strip().split("\n")[1:] # 첫 번째 라인을 제외하고 처리
records = []
for l in lines:
(name, gender) = l.split(",") # l = "Keeyong,M" -> [ 'keeyong', 'M' ]
records.append([name, gender])
logging.info("Transform ended")
return records
def load(**context):
logging.info("load started")
schema = context["params"]["schema"]
table = context["params"]["table"]
records = context["task_instance"].xcom_pull(key="return_value", task_ids="transform")
"""
records = [
[ "Keeyong", "M" ],
[ "Claire", "F" ],
...
]
"""
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
cur = get_Redshift_connection()
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema}.name_gender;")
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = f"IINSERT INTO {schema}.name_gender VALUES ('{name}', '{gender}')"
cur.execute(sql)
cur.execute("COMMIT;") # cur.execute("END;")
except (Exception, psycopg2.DatabaseError) as error:
print("Error Msg", error)
cur.execute("ROLLBACK;")
raise
logging.info("load done")
dag = DAG(
dag_id = 'name_gender_v4',
start_date = datetime(2023,4,6), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *', # 적당히 조절
max_active_runs = 1,
catchup = False,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
# 'on_failure_callback': slack.on_failure_callback,
}
)
extract = PythonOperator(
task_id = 'extract',
python_callable = extract,
params = {
'url': Variable.get("csv_url")
},
dag = dag)
transform = PythonOperator(
task_id = 'transform',
python_callable = transform,
params = {
},
dag = dag)
load = PythonOperator(
task_id = 'load',
python_callable = load,
params = {
'schema': '#####', ## 자신의 스키마로 변경
'table': 'name_gender'
},
dag = dag)
extract >> transform >> load● Variable를 이용해 CSV parameter 넘기기
● csv_url: ○ https://s3-geospatial.s3-us-west-2.amazonaws .com/name_gender.csv
○ 값을 암호화하려면 (*****)
Connections and Variables
● Connections
○ This is used to store some connection related info such as hostname, port number, and access credential
(호스트 이름, 포트 번호, 액세스 자격 증명 등 일부 연결 관련 정보를 저장하는 데 사용)
○ Postgres connection or Redshift connection info can be stored here
(Postgres 연결 또는 Redshift 연결 정보를 저장)
● Variables
○ Used to store API keys or some configuration info (API 키 또는 일부 구성 정보를 저장하는 데 사용)
○ Use “access” or “secret” in the name if you want its value to be encrypted (값을 암호화하려면 이름에 "access" 또는 "secret"를 사용)
○ We will practice this(우리는 이걸 연습해볼 것이다.)
Web UI
Airflow Connections
Airflow Variables
Redshift Connection 설정 (Data Warehouse)
Airflow Web UI after the Successful Installation
'Data Engineering > 실리콘밸리에서 날아온 데이터 엔지니어링 스타터 키트' 카테고리의 다른 글
| [5주차] Airflow Deepdive 2 - API를 사용해서 DAG 만들어보기 (0) | 2023.09.14 |
|---|---|
| [4주차] Assignment (0) | 2023.09.10 |
| [4주차] Airflow Deepdive - Airflow로 데이터 파이프라인 만들기 (1) (0) | 2023.09.05 |
| [4주차] 데이터베이스 트랜잭션 (0) | 2023.09.05 |
| [3주차] Assignment (0) | 2023.08.31 |