
정수 인코딩이란?
전처리된 텍스트 데이터를 컴퓨터가 분석에 활용할 수 있게 하려면 숫자 데이터로 변환해야 합니다. 이를 위한 여러 방법이 있는데요. 대표적으로 정수 인코딩이 있습니다. 정수 인코딩은 토큰화된 각 단어에 특정 정수를 맵핑하여 고유 번호로 사용하는 방법입니다.
단어 토큰에 정수 인덱스를 부여하는 방법은 다양한데요. 그 중 가장 일반적인 방법은 단어의 등장 빈도를 기준으로 정렬한 다음 인덱스를 부여하는 방식입니다.
정수 인코딩 하기
정수 인코딩을 하면 더 이상 추가적인 전처리를 할 수 없습니다. 때문에 모든 전처리 과정이 끝난 코퍼스를 가지고 정수 인코딩을 해야 합니다. 자연어 전처리 적용 II 레슨에서 작업한 df['cleaned_tokens']을 이용해 진행해 보겠습니다. 현재 데이터 프레임이 어떤 상태였는지 확인부터 해 볼게요.
df[['cleaned_tokens']]
데이터 프레임의 각 로우에 정제 작업이 완료된 토큰들이 리스트 형태로 들어있습니다. 이제 이 데이터들을 정수 인코딩해 볼건데요. 먼저 한 로우부터 정수 인코딩을 적용해 보고, 그 다음에 전체 데이터 프레임에 정수 인코딩을 적용해 보겠습니다.
하나의 로우 정수 인코딩
df['cleaned_tokens']의 5번째 로우에 있는 데이터를 가지고 정수 인코딩을 적용해 볼게요. 정수 인코딩을 하기 위해선 코퍼스에 포함된 단어 토큰들의 등장 빈도를 계산해서 빈도수가 높은 순서로 정렬해야 합니다.
tokens = df['cleaned_tokens'][4]
vocab = Counter(tokens)
vocab = vocab.most_common()
print(vocab)
단어와 코퍼스 안에서 해당 단어의 등장 빈도가 튜플 형태로 매칭되어 리스트에 저장되었네요. 또한, 빈도수 기준으로 정렬도 잘 되어있습니다. 해당 결과를 가지고 각 단어에 인덱스를 부여해 보겠습니다.
word_to_idx = {}
i = 0
for (word, frequency) in vocab:
i = i + 1
word_to_idx[word] = i
print(word_to_idx)
인덱스가 잘 부여됐네요. 이제, 토큰들을 부여된 인덱스로 바꾸겠습니다.
encoded_idx = []
for token in tokens:
idx = word_to_idx[token]
encoded_idx.append(idx)
print(encoded_idx)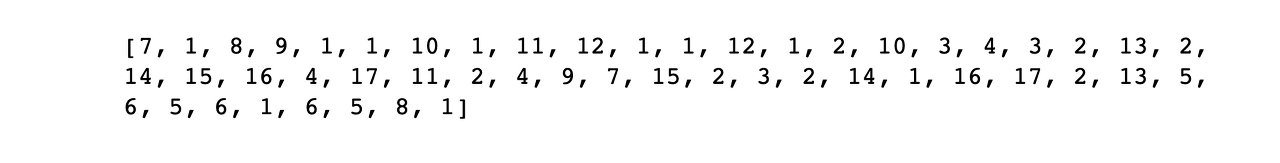
각 토큰에 정수가 잘 부여됐습니다.
전체 데이터 프레임 정수 인코딩
데이터 프레임에 있는 모든 로우들로 정수 인코딩을 하려면 먼저 전체 코퍼스의 토큰들을 전부 합하여 단어의 등장 빈도를 계산해야 합니다. 그래야 정수 인덱스가 각 코퍼스에 포함된 토큰들마다 동일하게 부여될 수 있습니다.
모든 로우에 있는 토큰들을 합쳐서 빈도를 계산할 때에는 sum() 함수가 사용됩니다. sum() 함수에 모든 코퍼스들과 []를 파라미터로 넘겨 주면 하나의 합쳐진 토큰 리스트가 결과로 나옵니다.
tokens = sum(df['cleaned_tokens'], [])
print(tokens)
이렇게 합쳐진 토큰 리스트로 빈도를 계산하고 많이 등장한 순으로 정렬하여 정수 인덱스를 부여하겠습니다.
word_to_idx = {}
i = 0
tokens = sum(df['cleaned_tokens'], [])
vocab = Counter(tokens)
vocab = vocab.most_common()
for (word, frequency) in vocab:
i = i + 1
word_to_idx[word] = i
결과를 확인해 볼게요
print(word_to_idx)
이제 만들어진 정수 인덱스를 가지고 데이터 프레임의 각 로우에 있는 토큰들을 정수 인코딩해 주겠습니다.
해당 작업을 해주는 함수 idx_encoder()를 만들어서 apply() 함수로 전체 데이터 프레임에 적용해 볼게요.
def idx_encoder(tokens, word_to_idx):
encoded_idx = []
for token in tokens:
idx = word_to_idx[token]
encoded_idx.append(idx)
return encoded_idx
df['integer_encoded'] = df['cleaned_tokens'].apply(lambda x: idx_encoder(x, word_to_idx))
df[['integer_encoded']]
모든 코퍼스의 토큰들에 정수 인덱스가 잘 부여됐습니다.
'Data Analysis > Natural Language Processing(NLP)' 카테고리의 다른 글
| 패딩(Padding) (0) | 2023.06.18 |
|---|---|
| 정수 인코딩 실습 (0) | 2023.06.15 |
| 자연어 전처리 후 통합하기 (0) | 2023.06.14 |
| 자연어 전처리 적용 II (0) | 2023.06.14 |
| 표제어 추출 실습 (0) | 2023.06.10 |