
이번 포스팅에서는 전처리된 자연어 데이터를 활용한 감성 분석을 배워 보겠습니다.
감성 분석이란
자연어에 담긴 어조가 긍정적인지, 부정적인지, 혹은 중립적인지 확인하는 작업을 감성 분석(Sentiment Analysis)이라고 합니다. 예를 들어 어떤 상품의 리뷰가 아래와 같이 작성됐다고 할게요.
- I love it.
- I hate this.
첫 번째 리뷰에 등장하는 love는 긍정적인 의미입니다. 때문에 해당 리뷰가 많이 달린 상품은 고객 반응이 좋은 것으로 해석됩니다. 반대로 hate는 부정적인 의미이기 때문에, 해당 리뷰가 많이 달린 상품은 고객 불만족이 큰 것으로 해석되죠.
이렇게 코퍼스에 담긴 의미가 긍정인지 부정인지를 구분할 수 있으면 재미있는 인사이트를 얻을 수 있습니다. 하지만 수많은 리뷰들을 사람이 하나 하나 읽어보고 분류하는 건 굉장히 비효율적입니다. 이런 상황에서 자연어 처리의 감성 분석이 사용됩니다.
감성 분석의 결과를 잘 활용하면 제품 개발, 서비스 개선, 시장 조사 등 다양한 용도로 활용할 수 있습니다.
감성 분석 종류
감성 분석을 하려면 코퍼스에 포함되는 특정 단어의 감성을 판단하는 기준이 필요한데요. 그 기준을 만드는 방법에 따라 두 가지 접근법이 있습니다.
규칙 기반 감성 분석
규칙 기반 감성 분석은 감성 어휘 사전을 기준으로 특정 단어가 긍정적인지, 부정적인지, 중립적인지를 분류하는 방법입니다. 여기서 감성 어휘 사전이란 사람이 특정 단어를 보고 직접 긍정, 부정, 중립 수치를 기재해 놓은 단어들의 집합입니다.
예를 들어 Love와 Hate라는 단어가 있다고 가정해 볼게요. 사람들은 직관적으로 Love를 긍정적인 단어, Hate를 부정적인 단어로 쉽게 구분할 수 있겠죠? 이걸 긍정, 부정, 중립을 나타내는 수치로 표현할 수 있습니다. 이렇게 굉장히 많은 단어들의 감성 지수를 사람들의 판단에 따라 정리해 두고, 그 수치를 가지고 감성을 분류하는 것이 규칙 기반 감성 분석입니다.

해당 방법은 직관적으로 이해하기 쉽고, 연산 속도도 빠릅니다. 또 굉장히 안정적이고 일관된 성능을 보입니다. 하지만 감성 어휘 사전에 없는 단어들로 이루어진 코퍼스는 분석이 제한된다는 단점이 있습니다.
머신러닝 기반 감성 분석
머신러닝 기반 감성 분석은 다수의 코퍼스들을 통해 긍정 단어와 부정 단어를 구분하는 모델을 학습시켜 그 모델을 기반으로 감성 지수를 확인하는 방법입니다.
머신러닝을 배우지 않은 분들이라면 모델과 학습이 조금 생소한 개념일 수 있는데요. 모델은 특정한 분석 방법을 적용시켜서 결과물을 도출하는 프로그램을 의미하고, 학습은 모델에게 데이터를 제공해 분석을 시키는 과정을 뜻합니다. 이렇게 사람이 임의로 만들어 둔 기준 없이 모델이 찾은 기준을 가지고 감성을 구분하는 게 머신러닝 기반 감성 분석입니다.
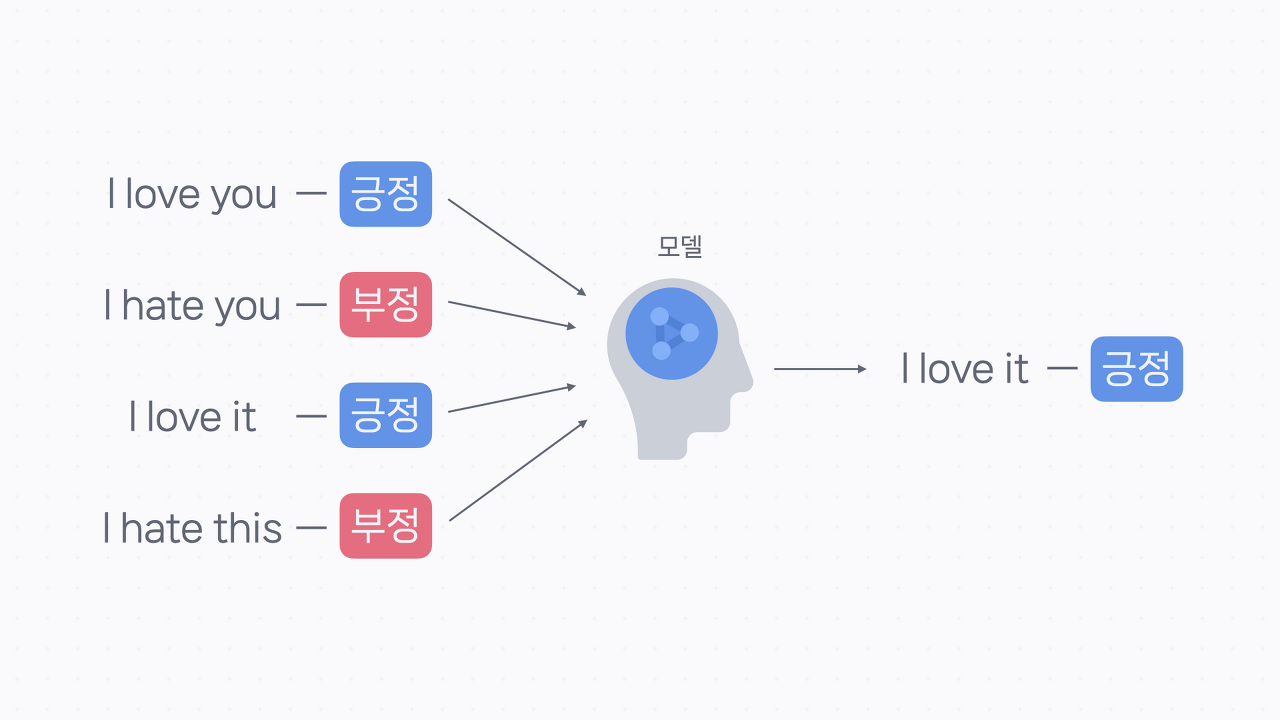
해당 방법은 감성 어휘 사전에 없는 단어들로 이루어졌거나 오타가 많은 코퍼스를 분석할 때 효과적입니다. 하지만 모델링을 위한 대량의 훈련 데이터가 필요하고, 분석 결과가 규칙 기반 감성 분석보다 안정적이지 않다는 단점도 있습니다.
이번 포스팅에서는 규칙 기반 감성 분석만 다루도록 하겠습니다.
'Data Analysis > Natural Language Processing(NLP)' 카테고리의 다른 글
| SentiWordNet (0) | 2023.07.04 |
|---|---|
| WordNet (0) | 2023.07.04 |
| 패딩(Padding) (0) | 2023.06.18 |
| 정수 인코딩 실습 (0) | 2023.06.15 |
| 정수 인코딩(Integer Encoding) (0) | 2023.06.15 |