
scikit-learn 사용해보기
예제 데이터 제공
scikit-learn은 예제 데이터 세트를 제공합니다. 데이터가 없는 상황에서 원하는 기능을 간단하게 사용해 보고 싶을 때 유용하게 사용할 수 있는데요. 이번 튜토리얼에서는 와인 품질 관련 정보가 담긴 데이터를 사용해 볼게요.
sklearn.dataset 패키지에 있는 load_wine()로 원하는 데이터 세트를 가져올 수 있습니다. 데이터는 data로(wine.data), 변수 이름은 feature_names로(wine.feature_names) 접근할 수 있는데요. 이 둘을 이용해 하나의 데이터 프레임을 만들어 볼게요.
from sklearn.dataset import load_wine
import pandas as pd
wine = load_wine()
wine_df = pd.DataFrame(wine.data, columns=wine.feature_names)만들어진 데이터 프레임을 확인해 보겠습니다.
wine_df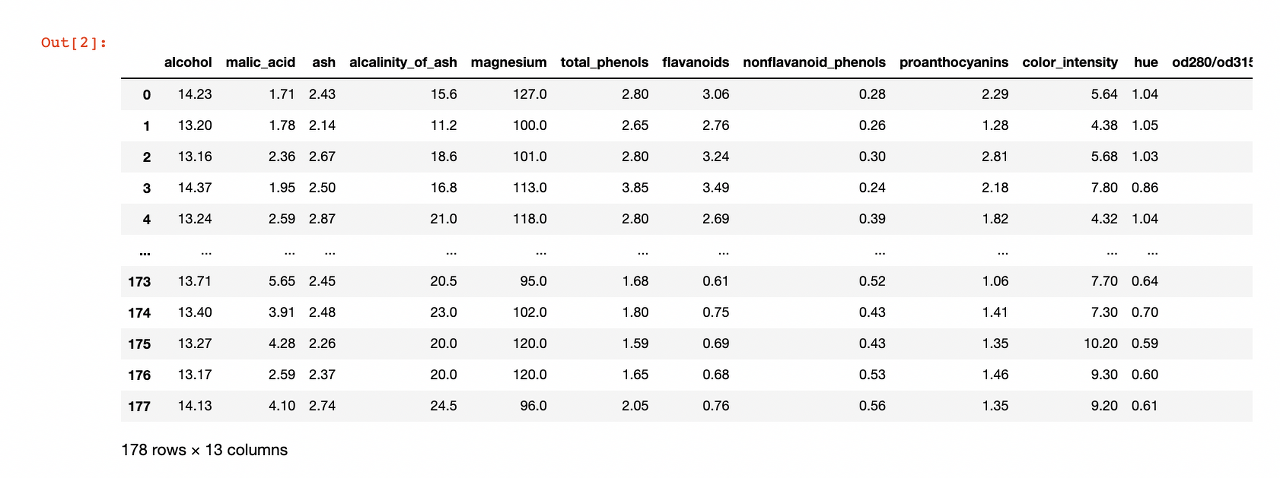
잘 불러와졌네요.
scikit-learn은 이외에도 다양한 샘플 데이터들을 제공합니다. 불러오는 함수만 다르고 사용하는 방법은 유사하기 때문에 어떤 데이터 세트가 있는지만 알면 쉽게 사용할 수 있는데요. 필요하신 분들은 링크를 참고해 주세요.
전처리
서로 단위가 다른 데이터로 분석을 진행하면 특정 변수의 영향력이 커져서 결과가 잘못될 수 있습니다. 그래서, 사전에 단위를 통일하는 작업이 필요한데요. 그 중 표준화(Standardization)라는 방법이 있습니다. 머신러닝뿐만 아니라 데이터 분석을 하는 여러 상황에서 많이 하는 작업입니다.
sklearn.preprocessing 패키지의 StandardScaler()를 사용하면 별도의 연산 없이 쉽게 표준화 할 수 있습니다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
wine_df = pd.DataFrame(scaler.fit_transform(wine_df), columns=wine.feature_names)
wine_df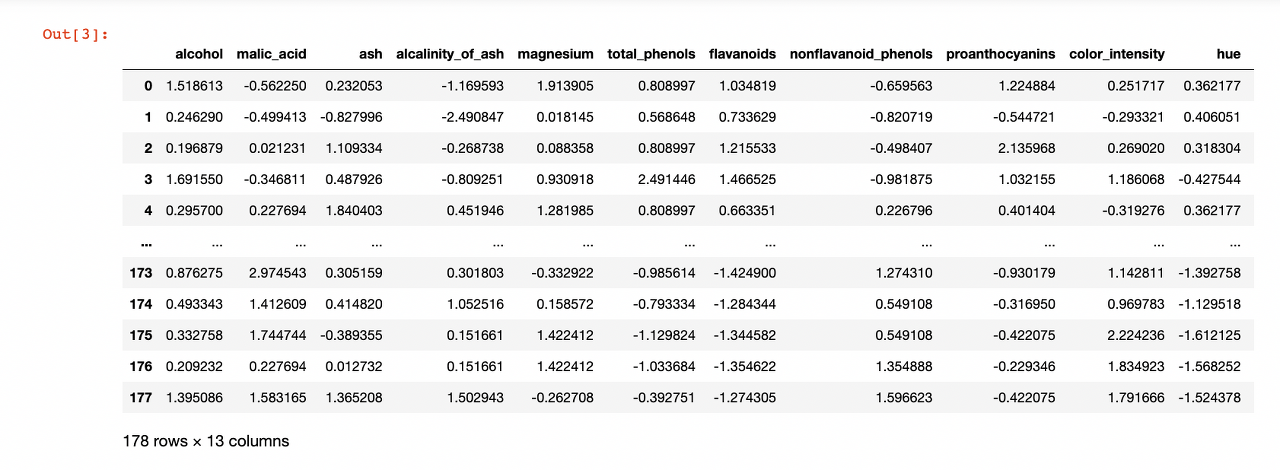
모든 열의 값이 평균 0, 분산 1이 되도록 표준화 되었습니다.
이외에도 scikit-learn에는 다양한 기능들이 있습니다. 특히, 복잡한 수식으로 구현된 여러 머신러닝 모델들을 쉽게 사용할 수 있도록 준비되어 있습니다.
혹시 더 많은 scikit-learn의 기능들이 궁금하시다면 링크를 참고해주세요.
'Data Analysis > Data Analysis Practice' 카테고리의 다른 글
| 데이터 분석가가 갖춰야 할 9가지 역량 (0) | 2023.06.19 |
|---|---|
| 주피터 노트북에서 파이썬 모듈 자동 리로드하기 (2) | 2023.06.09 |
scikit-learn 사용해보기
예제 데이터 제공
scikit-learn은 예제 데이터 세트를 제공합니다. 데이터가 없는 상황에서 원하는 기능을 간단하게 사용해 보고 싶을 때 유용하게 사용할 수 있는데요. 이번 튜토리얼에서는 와인 품질 관련 정보가 담긴 데이터를 사용해 볼게요.
sklearn.dataset 패키지에 있는 load_wine()로 원하는 데이터 세트를 가져올 수 있습니다. 데이터는 data로(wine.data), 변수 이름은 feature_names로(wine.feature_names) 접근할 수 있는데요. 이 둘을 이용해 하나의 데이터 프레임을 만들어 볼게요.
from sklearn.dataset import load_wine
import pandas as pd
wine = load_wine()
wine_df = pd.DataFrame(wine.data, columns=wine.feature_names)만들어진 데이터 프레임을 확인해 보겠습니다.
wine_df잘 불러와졌네요.
scikit-learn은 이외에도 다양한 샘플 데이터들을 제공합니다. 불러오는 함수만 다르고 사용하는 방법은 유사하기 때문에 어떤 데이터 세트가 있는지만 알면 쉽게 사용할 수 있는데요. 필요하신 분들은 링크를 참고해 주세요.
전처리
서로 단위가 다른 데이터로 분석을 진행하면 특정 변수의 영향력이 커져서 결과가 잘못될 수 있습니다. 그래서, 사전에 단위를 통일하는 작업이 필요한데요. 그 중 표준화(Standardization)라는 방법이 있습니다. 머신러닝뿐만 아니라 데이터 분석을 하는 여러 상황에서 많이 하는 작업입니다.
sklearn.preprocessing 패키지의 StandardScaler()를 사용하면 별도의 연산 없이 쉽게 표준화 할 수 있습니다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
wine_df = pd.DataFrame(scaler.fit_transform(wine_df), columns=wine.feature_names)
wine_df모든 열의 값이 평균 0, 분산 1이 되도록 표준화 되었습니다.
이외에도 scikit-learn에는 다양한 기능들이 있습니다. 특히, 복잡한 수식으로 구현된 여러 머신러닝 모델들을 쉽게 사용할 수 있도록 준비되어 있습니다.
혹시 더 많은 scikit-learn의 기능들이 궁금하시다면 링크를 참고해주세요.
'Data Analysis > Data Analysis Practice' 카테고리의 다른 글
| 데이터 분석가가 갖춰야 할 9가지 역량 (0) | 2023.06.19 |
|---|---|
| 주피터 노트북에서 파이썬 모듈 자동 리로드하기 (2) | 2023.06.09 |