
What is Data Engineering? 데이터 엔지니어링은 무엇일까?
데이터 엔지니어는 다양한 역할을 수행
- 데이터 웨어하우스 관리
- 데이터 파이프라인 구축 및 관리
> 데이터 파이프라인 == ETL(Extract 수집, Transform 변환, Load 적재) == Data Job == DAG
- 데이터 파이프라인의 종류
> 배치형 프로세스(Batch Processing) VS 실시간 프로세스(Realtime Processing)
> 요약 데이터 생성(Summary Data Generation : dbt - Analytics Engineer이 하는 일)
- 이벤트 수집(Event Collection)
> 유저 행동 데이터(User's Behavioral data)
데이터 엔지니어가 알아야 하는 기술은?
- SQL : Hive, Presto, Spark SQL, ....
- Programming Language : Python, Scala, Java
- ETL/ELT Scheduler : Airflow, ...
- Lagrge Scale Computing Platform : Spark/YARN
- Cloud Computing : AWS
- Container Technology : K8s, Docker
- Knowledge : 머신러닝, A/B 테스트, 통계학
What is Data Warehouse? 데이터 웨어하우스란 무엇인가? 데이터 분석용 전용 데이터베이스
- 데이터 웨어하우스는 Production Database로 부터 분리되어야한다.
- 상황에 따라 최적 옵션을 찾아야한다.
> 소규모로 시작하여 데이터가 증가하면 확장성이 뛰어난 솔루션으로 전환할 수 있어야한다.
> AWS Redshift, Snowflake, Google Cloud BigQuery, 오픈 소스 Hive/Spark/Presto
- 데이터 웨어하우스가 운영 데이터베이스가 아니다.
> 운영 데이터베이스와 분리되어야 한다.
> OLAP(온라인 분석 처리) VS OLTP(온라인 트랜잭션 처리)
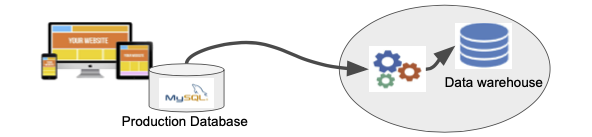
Central Data Storage of your Company, 기업의 중앙 데이터 스토리지
- 데이터 웨어하우스는 "진정한" 데이터 조직으로 거듭나기 위한 첫 단계
> 다양한 소스의 원시 데이터 저장 : ETL
> 원시 데이터에서 요약 테이블 생성(및 기타 요약) * 이과정은 ETL이 아니라 ELT
- 고정 비용 옵션(Fixed Cost Option) VS 변동 비용 옵션(Variable Cost Option)
> 변동비용 옵션은 스토리지와 컴퓨팅의 분리된 용량 증가를 제공한다.(BigQuery and Snowflake)
> 고정 비용 옵션은 안정적인 비용 예측 가능(RedShift 또는 대부분의 On-premise 데이터웨어하우스(오픈소스 기반))
RedShift Introduction, AWS가 제공해주는 데이터 웨어하우스인 RedShift에 대해 알아보자
REDSHIFT는 AWS의 확장 가능한 SQL 엔진(데이터 웨어하우스)
- 서버 클러스터에서 최대 2PB의 데이터를 제공한다.
- OLAP
> 응답 시간은 1초 미만이다.
> 고객 대면 서비스에서는 사용하지 않는 것이 좋다.
- Columnar Storage(컬럼형 스토리지)
> 테이블에서 열을 추가하거나 삭제하거나 이름을 변경하는 속도가 매우 빠르다.
> 열 단위로 압축이 사용된다.
- Bulk-Update 지원(대량 업데이트 지원)
- CSV/JSON 파일을 S3에 업로드하고 S3에서 RedShift로 복사가 가능하다.
- 고정용량 SQL 엔진
- 모든 웨어하우스는 데이터의 크기, 속도 때문에 Primary key를 보장하지 않는다.
- PoresSQL 8.X와 호환
다음 서비스와 완벽한 통합
- S3, EMR, Kinesis, DynamoDB, RDS 등
- S3에서 백업 지원
> 보통 이것을 Snapshot이라고 한다. 기본적으로 같은 AWS 영역에 있다.
RedShift의 확장
- Python 기반 사용자 정의 함수 지원(python 2.x)
- 캐싱(caching) 지원(2017~)
- Athena(구조화되지 않은 데이터를 Redshift로 이동)

Bulk-Upade
- 데이터를 하나씩 insert하는 것이 아니라, 파일로(대량으로) 한번에 bulk적재(copy) 한다.
- 데이터 웨어하우스 특성 상, SQL insert into하면 시간이 너무 많이 소요된다.
> 이러한 이유로 데이터 웨어하우스 솔루션은 기본적으로 insert가 아닌 copy를 따로 한다.

How to Access RedShift? Redshift엔 어떻게 접근 할까?
RedShift에 접근하는 방법
- 분석 툴 활용 (Tableau, Looker)
> 기능이 너무 많고, 전담 분석가가 할 가능성이 높다.
- JDBC / ODBC 라이브러리
> 모든 PostgreSQL 8.0.x는 호환
> Python에서 Psycopg2로 접근
- SQL Client 사용
> Postico(MAC)
> SQL Workbench
> DBeaver
> DataGrip(JetBrain 사용중이라면 강추)
- Python Notebook
> Google Colab
RedShift Schema

- Raw_data : 외부에서 적재된 테이블 (ETL)
- Ananlytics : ELT로 만들어진 테이블
- Adhoc
'Data Engineering > 실리콘밸리에서 날아온 데이터 엔지니어링 스타터 키트' 카테고리의 다른 글
| [2주차] Assignment (0) | 2023.08.25 |
|---|---|
| [2주차] SQL for Data Engineers(2) (0) | 2023.08.22 |
| [2주차] SQL for Data Engineers(1) (3) | 2023.08.22 |
| [1주차] Assignment (0) | 2023.08.18 |
| [1주차] 데이터팀의 역할 (1) | 2023.08.13 |