
-
Incremental Update가 실패하면?
-
Incremental Update
-
Backfill의 용이성 여부 → 데이터 엔지니어 삶에 직접적인 영향!
-
보통 Daily DAG를 작성한다고 하면 어떻게 할까?
-
그런데 지난 1년치 데이터를 Backfill 해야한다면?
-
어떻게 ETL을 구현해놓으면 이런 일이 편해질까?
-
어떻게 ETL을 구현해놓으면 이런 일이 편해질까?
-
Airflow: 보통 Daily DAG를 작성한다고 하면 어떻게 할까?
-
start_date: Daily Incremental Update를 구현해야 한다면?
-
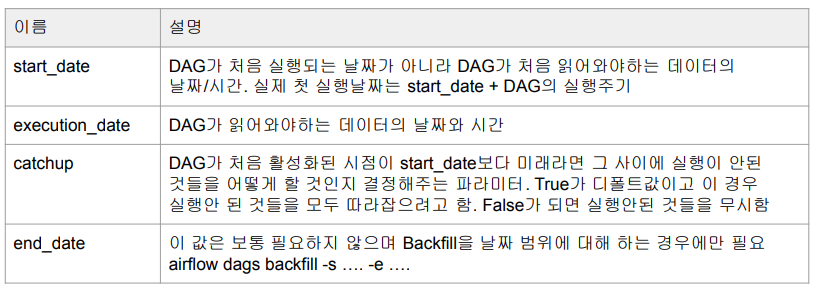
Backfill과 관련된 Airflow 변수들
관리하는 데이터 파이프라인의 수가 늘어나면 이 중의 몇은 항상 실패하게 되며 이를 어떻게 관리하느냐가 데이터 엔지니어의 삶에 큰 영향을 준다. start_date과 execution_date
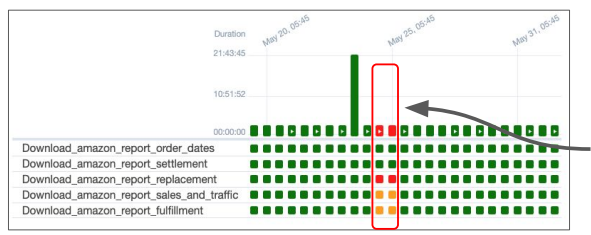
Incremental Update가 실패하면?
하루에 한번 동작하고 Incremental하게 업데이트하는 파이프라인이라면?
실패한 부분을 재실행하는 것이 중요하다.
Incremental Update
● Incremental Update란 ?
○ 새로운 데이터를 전체 데이터 세트에 다시 처리하는 대신 변경된 데이터만 처리하여 데이터 저장 및 관리를 최적화하는 방법
● 다시 한번 가능하면 Full Refresh를 사용하는 것이 좋음
○ 문제가 생겨도 다시 실행하면 됨
● Incremental Update는 효율성이 더 좋을 수 있지만 운영/유지보수의 난이도가 올라감
○ 실수등으로 데이터가 빠지는 일이 생길 수 있음
○ 과거 데이터를 다시 다 읽어와야하는 경우 다시 모두 재실행을 해주어야함
Backfill의 용이성 여부 → 데이터 엔지니어 삶에 직접적인 영향!
● Backfill의 정의
○ 실패한 데이터 파이프라인을 재실행 혹은 읽어온 데이터들의 문제로 다시 다 읽어와야하는 경우를 의미
● Backfill 해결은 Incremental Update에서 복잡해짐
○ Full Refresh에서는 간단. 그냥 다시 실행하면 됨
● 즉 실패한 데이터 파이프라인의 재실행이 얼마나 용이한 구조인가?
○ 이게 잘 디자인된 것이 바로 Airflow
보통 Daily DAG를 작성한다고 하면 어떻게 할까?
● 지금 시간을 기준으로 어제 날짜를 계산하고 그 날짜에 해당하는 데이터를 읽어옴
from datetime import datetime, timedelta
# 지금 시간 기준으로 어제 날짜를 계산
y = datetime.now() - timedelta(1)
yesterday = datetime.strftime(y, '%Y-%m-%d')
yesterday = context["execution_date”]
# yesterday에 해당하는 데이터를 소스에서 읽어옴
# 예를 들어 프로덕션 DB의 특정 테이블에서 읽어온다면
sql = f"SELECT * FROM table WHERE DATE(ts) = '{yesterday}'"
그런데 지난 1년치 데이터를 Backfill 해야한다면?
● 기존 ETL 코드를 조금 수정해서 지난 1년치 데이터에 대해 돌린다
from datetime import datetime, timedelta
# y = datetime.now() - timedelta(1)
# yesterday = datetime.strftime(y, '%Y-%m-%d')
yesterday = '2023-01-01' # 이 부분을 365번 바꿔서 실행하던지 루프를 돌리는 걸로 변경
# yesterday에 해당하는 데이터를 소스에서 읽어옴
# 예를 들어 프로덕션 DB의 특정 테이블에서 읽어온다면
sql = f"SELECT * FROM table WHERE DATE(ts) = '{yesterday}'"● 실수하기 쉽고 수정하는데 시간이 걸림
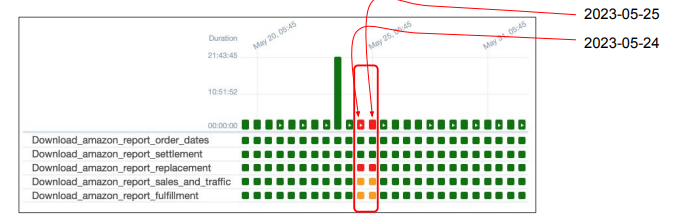
어떻게 ETL을 구현해놓으면 이런 일이 편해질까?
● 시스템적으로 이걸 쉽게 해주는 방법을 구현한다
○ DAG별로 날짜시간별로 실행 결과를 기록하고 성공 여부 기록: 나중에 결과를 쉽게 확인
○ 이 날짜를 시스템에서 ETL의 인자로 제공
○ 데이터 엔지니어는 읽어와야하는 데이터의 날짜를 계산하지 않고 시스템이 지정해준 날짜를 사용
어떻게 ETL을 구현해놓으면 이런 일이 편해질까?
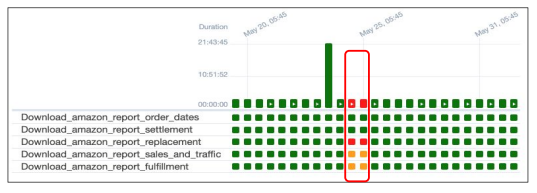
● Airflow의 접근방식
○ ETL 별로 실행 날짜/시간과 결과를 메타데이터 데이터베이스에 기록
○ 모든 DAG 실행에는 “execution_date”이 존재하며 이게 바로 읽어와야할 데이터의 날짜와 시간
■ execution_date으로 채워야하는 날짜와 시간이 넘어옴
○ 이를 바탕으로 데이터를 갱신하도록 코드를 작성해야함
○ 장점: backfill이 쉬워짐
Airflow: 보통 Daily DAG를 작성한다고 하면 어떻게 할까?
● 운영과 Backfill을 동일한 코드로 가능
from datetime import datetime, timedelta
yesterday = context["execution_date”]
# yesterday에 해당하는 데이터를 소스에서 읽어옴
# 예를 들어 프로덕션 DB의 특정 테이블에서 읽어온다면
sql = f"SELECT * FROM table WHERE DATE(ts) = '{yesterday}'"
start_date: Daily Incremental Update를 구현해야 한다면?
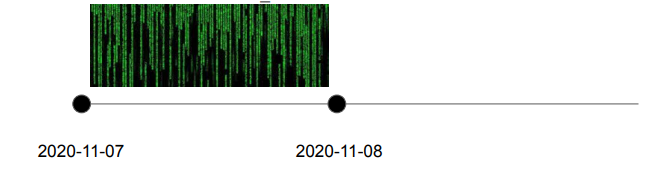
● 예를 들어 2020년 11월 7일의 데이터부터 매일매일 하루치 데이터를 읽어온다고 가정
● 이 경우 언제부터 해당 ETL이 동작해야하나?
○ 2020년 11월 8일
● 다르게 이야기하면 2020년 11월 8일날 동작하지만 읽어와야 하는 데이터의 날짜는?
○ 2020년 11월 7일: 이게 start_date이 됨
● Airflow의 start_date은 시작 날짜라기는 보다는 처음 읽어와야하는 데이터의 날짜임
● execution_date은 읽어와야하는 데이터의 날짜로 설정됨
Backfill과 관련된 Airflow 변수들
'Data Engineering > 실리콘밸리에서 날아온 데이터 엔지니어링 스타터 키트' 카테고리의 다른 글
| [5주차] Airflow Deepdive 2 - API를 사용해서 DAG 만들어보기 (0) | 2023.09.14 |
|---|---|
| [4주차] Assignment (0) | 2023.09.10 |
| [4주차] Airflow Deepdive - Airflow로 데이터 파이프라인 만들기 (2) (2) | 2023.09.05 |
| [4주차] Airflow Deepdive - Airflow로 데이터 파이프라인 만들기 (1) (0) | 2023.09.05 |
| [4주차] 데이터베이스 트랜잭션 (0) | 2023.09.05 |
관리하는 데이터 파이프라인의 수가 늘어나면 이 중의 몇은 항상 실패하게 되며 이를 어떻게 관리하느냐가 데이터 엔지니어의 삶에 큰 영향을 준다. start_date과 execution_date
Incremental Update가 실패하면?
하루에 한번 동작하고 Incremental하게 업데이트하는 파이프라인이라면?
실패한 부분을 재실행하는 것이 중요하다.
Incremental Update
● Incremental Update란 ?
○ 새로운 데이터를 전체 데이터 세트에 다시 처리하는 대신 변경된 데이터만 처리하여 데이터 저장 및 관리를 최적화하는 방법
● 다시 한번 가능하면 Full Refresh를 사용하는 것이 좋음
○ 문제가 생겨도 다시 실행하면 됨
● Incremental Update는 효율성이 더 좋을 수 있지만 운영/유지보수의 난이도가 올라감
○ 실수등으로 데이터가 빠지는 일이 생길 수 있음
○ 과거 데이터를 다시 다 읽어와야하는 경우 다시 모두 재실행을 해주어야함
Backfill의 용이성 여부 → 데이터 엔지니어 삶에 직접적인 영향!
● Backfill의 정의
○ 실패한 데이터 파이프라인을 재실행 혹은 읽어온 데이터들의 문제로 다시 다 읽어와야하는 경우를 의미
● Backfill 해결은 Incremental Update에서 복잡해짐
○ Full Refresh에서는 간단. 그냥 다시 실행하면 됨
● 즉 실패한 데이터 파이프라인의 재실행이 얼마나 용이한 구조인가?
○ 이게 잘 디자인된 것이 바로 Airflow
보통 Daily DAG를 작성한다고 하면 어떻게 할까?
● 지금 시간을 기준으로 어제 날짜를 계산하고 그 날짜에 해당하는 데이터를 읽어옴
from datetime import datetime, timedelta
# 지금 시간 기준으로 어제 날짜를 계산
y = datetime.now() - timedelta(1)
yesterday = datetime.strftime(y, '%Y-%m-%d')
yesterday = context["execution_date”]
# yesterday에 해당하는 데이터를 소스에서 읽어옴
# 예를 들어 프로덕션 DB의 특정 테이블에서 읽어온다면
sql = f"SELECT * FROM table WHERE DATE(ts) = '{yesterday}'"
그런데 지난 1년치 데이터를 Backfill 해야한다면?
● 기존 ETL 코드를 조금 수정해서 지난 1년치 데이터에 대해 돌린다
from datetime import datetime, timedelta
# y = datetime.now() - timedelta(1)
# yesterday = datetime.strftime(y, '%Y-%m-%d')
yesterday = '2023-01-01' # 이 부분을 365번 바꿔서 실행하던지 루프를 돌리는 걸로 변경
# yesterday에 해당하는 데이터를 소스에서 읽어옴
# 예를 들어 프로덕션 DB의 특정 테이블에서 읽어온다면
sql = f"SELECT * FROM table WHERE DATE(ts) = '{yesterday}'"● 실수하기 쉽고 수정하는데 시간이 걸림
어떻게 ETL을 구현해놓으면 이런 일이 편해질까?
● 시스템적으로 이걸 쉽게 해주는 방법을 구현한다
○ DAG별로 날짜시간별로 실행 결과를 기록하고 성공 여부 기록: 나중에 결과를 쉽게 확인
○ 이 날짜를 시스템에서 ETL의 인자로 제공
○ 데이터 엔지니어는 읽어와야하는 데이터의 날짜를 계산하지 않고 시스템이 지정해준 날짜를 사용
어떻게 ETL을 구현해놓으면 이런 일이 편해질까?
● Airflow의 접근방식
○ ETL 별로 실행 날짜/시간과 결과를 메타데이터 데이터베이스에 기록
○ 모든 DAG 실행에는 “execution_date”이 존재하며 이게 바로 읽어와야할 데이터의 날짜와 시간
■ execution_date으로 채워야하는 날짜와 시간이 넘어옴
○ 이를 바탕으로 데이터를 갱신하도록 코드를 작성해야함
○ 장점: backfill이 쉬워짐
Airflow: 보통 Daily DAG를 작성한다고 하면 어떻게 할까?
● 운영과 Backfill을 동일한 코드로 가능
from datetime import datetime, timedelta
yesterday = context["execution_date”]
# yesterday에 해당하는 데이터를 소스에서 읽어옴
# 예를 들어 프로덕션 DB의 특정 테이블에서 읽어온다면
sql = f"SELECT * FROM table WHERE DATE(ts) = '{yesterday}'"
start_date: Daily Incremental Update를 구현해야 한다면?
● 예를 들어 2020년 11월 7일의 데이터부터 매일매일 하루치 데이터를 읽어온다고 가정
● 이 경우 언제부터 해당 ETL이 동작해야하나?
○ 2020년 11월 8일
● 다르게 이야기하면 2020년 11월 8일날 동작하지만 읽어와야 하는 데이터의 날짜는?
○ 2020년 11월 7일: 이게 start_date이 됨
● Airflow의 start_date은 시작 날짜라기는 보다는 처음 읽어와야하는 데이터의 날짜임
● execution_date은 읽어와야하는 데이터의 날짜로 설정됨
Backfill과 관련된 Airflow 변수들
'Data Engineering > 실리콘밸리에서 날아온 데이터 엔지니어링 스타터 키트' 카테고리의 다른 글
| [5주차] Airflow Deepdive 2 - API를 사용해서 DAG 만들어보기 (0) | 2023.09.14 |
|---|---|
| [4주차] Assignment (0) | 2023.09.10 |
| [4주차] Airflow Deepdive - Airflow로 데이터 파이프라인 만들기 (2) (2) | 2023.09.05 |
| [4주차] Airflow Deepdive - Airflow로 데이터 파이프라인 만들기 (1) (0) | 2023.09.05 |
| [4주차] 데이터베이스 트랜잭션 (0) | 2023.09.05 |