
cleaned_by_freq = [word for word in tokenized_words if word not in uncommon_words]
print('빈도수 3 이상인 토큰 수:', len(cleaned_by_freq))코퍼스에는 아무 의미도 없거나 분석의 목적에 적합하지 않은 단어들도 포함됩니다. 이런 단어들은 전처리 과정에서 제거해야 하는데요. 그 과정을 정제(Cleaning)라고 합니다.
자연어 데이터를 정제하는 방법은 여러가지인데요. 그 중에서도 등장 빈도, 단어 길이, 불용어 등을 기준으로 많이 사용합니다. 하나씩 살펴볼게요.
등장 빈도가 적은 단어
코퍼스에 등장하는 빈도가 너무 적은 단어는 분석에 도움이 되지 않기 때문에 제거해야 합니다. 실제 데이터로 살펴볼게요. 데이터는 실습 레슨에서 사용했던 text.py 데이터를 그대로 사용하겠습니다.
text.py
TEXT = """Alice was beginning to get very tired of sitting by her sister on the bank, and of having nothing to do: once or twice she had peeped into the book her sister was reading, but it had no pictures or conversations in it, 'and what is the use of a book,' thought Alice 'without pictures or conversation?'
So she was considering in her own mind (as well as she could, for the hot day made her feel very sleepy and stupid), whether the pleasure of making a daisy-chain would be worth the trouble of getting up and picking the daisies, when suddenly a White Rabbit with pink eyes ran close by her.
There was nothing so very remarkable in that; nor did Alice think it so very much out of the way to hear the Rabbit say to itself, 'Oh dear! Oh dear! I shall be late!' (when she thought it over afterwards, it occurred to her that she ought to have wondered at this, but at the time it all seemed quite natural); but when the Rabbit actually took a watch out of its waistcoat-pocket, and looked at it, and then hurried on, Alice started to her feet, for it flashed across her mind that she had never before seen a rabbit with either a waistcoat-pocket, or a watch to take out of it, and burning with curiosity, she ran across the field after it, and fortunately was just in time to see it pop down a large rabbit-hole under the hedge.
In another moment down went Alice after it, never once considering how in the world she was to get out again.
The rabbit-hole went straight on like a tunnel for some way, and then dipped suddenly down, so suddenly that Alice had not a moment to think about stopping herself before she found herself falling down a very deep well.
Either the well was very deep, or she fell very slowly, for she had plenty of time as she went down to look about her and to wonder what was going to happen next. First, she tried to look down and make out what she was coming to, but it was too dark to see anything; then she looked at the sides of the well, and noticed that they were filled with cupboards and book-shelves; here and there she saw maps and pictures hung upon pegs. She took down a jar from one of the shelves as she passed; it was labelled 'ORANGE MARMALADE', but to her great disappointment it was empty: she did not like to drop the jar for fear of killing somebody, so managed to put it into one of the cupboards as she fell past it.
"""
text.py 파일에 있는 원문 텍스트를 한번 불러와 확인해 보겠습니다.
from text import TEXT
corpus = TEXT
print(corpus)
굉장히 긴 본문인데요. 해당 본문에서 등장 빈도가 2 이하인 단어들만 찾아 볼게요.
from collections import Counter
# 전체 단어 토큰 리스트
tokenized_words = word_tokenize(corpus)
# 파이썬의 Counter 모듈을 통해 단어의 빈도수 카운트하여 단어 집합 생성
vocab = Counter(tokenized_words)
# 빈도수가 2 이하인 단어 리스트 추출
uncommon_words = [key for key, value in vocab.items() if value <= 2]
# 빈도수가 2 이하인 단어들만 제거한 결과를 따로 저장
cleaned_by_freq = [word for word in tokenized_words if word not in uncommon_words]
한 부분씩 떼서 살펴보겠습니다. 먼저 단어의 빈도 계산에 사용할 Counter() 함수를 불러옵니다.
# Counter모듈 import
from collections import Counter
빈도수 계산을 위해선 먼저 코퍼스를 단어 기준으로 토큰화 해야 하는데요. 앞에서 배운 word_tokenize() 함수로 단어 토큰화할게요.
# 전체 단어 토큰 리스트
tokenized_words = word_tokenize(corpus)
다음으로, 단어의 등장 빈도를 Counter() 함수로 계산합니다. Counter()는 파라미터로 단어 리스트를 받고, 각 단어의 등장 빈도를 딕셔너리({단어: 등장 횟수}) 형태로 반환합니다.
# 파이썬의 Counter 모듈을 통해 단어의 빈도수 카운트하여 단어 집합 생성
vocab = Counter(tokenized_words)
vocab은 다음과 같은 형태로 저장되어 있습니다.
print(vocab)
생성된 단어 집합에서 빈도수가 2 이하인 단어 리스트만 추출하겠습니다. 해당 작업에는 list comprehension 문법을 사용할게요.
# 빈도수가 2 이하인 단어 리스트 추출
uncommon_words = [key for key, value in vocab.items() if value <= 2]
등장 빈도가 2 이하인 단어 리스트가 몇 개인지 확인해 볼까요?
print('빈도수가 2 이하인 단어 수:', len(uncommon_words))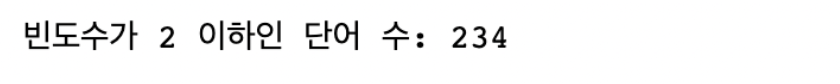
총 234개의 단어가 포함되어 있네요. 이제 uncommon_words에 없는 단어들만 cleaned_words에 저장하면 3회 이상 등장한 단어들만 남게 되겠죠?
cleaned_by_freq = [word for word in tokenized_words if word not in uncommon_words]
print('빈도수 3 이상인 토큰 수:', len(cleaned_by_freq))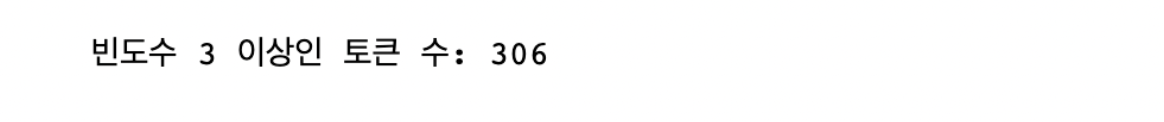
등장 빈도가 3회 이상인 단어 총 306개가 cleaned_by_freq에 저장되었습니다.
위의 예시에서는 정제를 위한 기준을 등장 빈도 2회 이하로 설정했는데요. 코퍼스의 특징과 분석의 목적에 따라 몇 회 이하 등장하는 단어를 정제할지는 달라집니다. 단어 토큰이 많은 코퍼스라면 빈도수 10 이하인 경우를 제거할 수도 있죠.
정제의 기준이 되는 숫자는 가장 적절한 숫자를 임의로 설정하면 됩니다. 다만, 보통 그런 최적의 정제 기준을 한번에 직관적으로 찾기는 어렵습니다. 그래서 같은 코퍼스를 여러번 전처리해 보고, 가장 좋은 결과가 나올 때의 정제 기준을 활용하는게 일반적입니다.
이렇게 여러번 전처리 과정을 반복해서 가장 결과가 잘 나오는 기준을 찾는 방식은 정제뿐만 아니라 모든 전처리 단계에서 동일하게 적용됩니다. 앞으로는 설명을 위해 임의의 기준을 잡고 전처리를 하지만, 실제 데이터 분석시에는 꼭 여러번 전처리해서 결과를 비교해 봐야 한다는 점 꼭 기억해 주세요.
길이가 짧은 단어
영어 단어의 경우, 알파벳 하나 또는 두개로 구성된 단어는 코퍼스의 의미를 나타내는데 중요하지 않을 가능성이 높습니다. 그래서 이런 단어들은 제거하는 게 좋습니다.
아래는 길이가 2 이하인 단어들을 제거하는 코드입니다. 단어 토큰들을 순회하면서 단어의 길이(len(word))가 2보다 큰 단어들만 cleaned_words에 넣으면 됩니다.
# 길이가 2 이하인 단어 제거
cleaned_by_freq_len = []
for word in cleaned_by_freq:
if len(word) > 2:
cleaned_by_freq_len.append(word)
정제 전과 후의 결과를 비교해 보겠습니다.
# 정제 결과 확인
print('정제 전:', cleaned_by_freq[:10])
print('정제 후:', cleaned_by_freq_len[:10])
콤마, I, be 등 큰 의미를 갖지 않는 단어들이 잘 제거되었습니다.
정제 함수 만들기
등장 빈도, 단어 길이 기준의 정제를 이후에 쉽게 사용할 수 있도록 따로 함수로 만들어 두겠습니다. 만들어진 함수는 preprocess.py라는 파일을 하나 따로 만들어서 추가해 두고 이후 포스팅에서도 필요할 때마다 불러와서 사용하겠습니다.
이후 포스팅에서 해당 함수들을 불러와 사용해야 하기 때문에, 실습 중인 주피터 노트북과 같은 디렉토리에 꼭 별도의 Python 파일을 만들어서 아래 함수들을 작성해 주세요.
preprocess.py
from collections import Counter
# 등장 빈도 기준 정제 함수
def clean_by_freq(tokenized_words, cut_off_count):
# 파이썬의 Counter 모듈을 통해 단어의 빈도수 카운트하여 단어 집합 생성
vocab = Counter(tokenized_words)
# 빈도수가 cut_off_count 이하인 단어 set 추출
uncommon_words = {key for key, value in vocab.items() if value <= cut_off_count}
# uncommon_words에 포함되지 않는 단어 리스트 생성
cleaned_words = [word for word in tokenized_words if word not in uncommon_words]
return cleaned_words
# 단어 길이 기준 정제 함수
def clean_by_len(tokenized_words, cut_off_length):
# 길이가 cut_off_length 이하인 단어 제거
cleaned_by_freq_len = []
for word in tokenized_words:
if len(word) > cut_off_length:
cleaned_by_freq_len.append(word)
return cleaned_by_freq_len'Data Analysis > Natural Language Processing(NLP)' 카테고리의 다른 글
| 불용어(Stopwords) (0) | 2023.06.08 |
|---|---|
| 정제 실습 (0) | 2023.06.06 |
| 단어 토큰화 실습 (0) | 2023.06.06 |
| 단어 토큰화(Word Tokenization) (0) | 2023.06.06 |
| 자연어 전처리란? (0) | 2023.06.06 |