
코퍼스에서 큰 의미가 없거나, 분석 목적에서 벗어나는 단어들을 불용어(stopword)라고 합니다. 이런 단어들은 정확한 분석을 방해하기 때문에 제거해야 합니다.
불용어(Stopwords) 정의하기
불용어 제거는 다음과 같은 방식으로 진행됩니다.
● 불용어를 모아 놓은 불용어 세트 준비
● 코퍼스의 각 단어 토큰이 불용어 세트에 포함되는지 확인
● 불용어 세트에 있는 단어 토큰은 분석에서 제외
불용어 제거에 활용되는 불용어 세트는 분석을 하는 사람이 코퍼스의 형태, 분석의 목적을 고려해 미리 만들어야 합니다. 그런데 매번 분석을 할 때만다 불용어 세트를 새롭게 만드는 것은 번거롭겠죠? 분명 코퍼스의 종류에 상관 없이 많이 사용되는 불용어들이 있기 때문에, 그런 것들은 미리 정의해 두고 필요할 때마다 불러와서 사용하면 훨씬 편리할 거 같습니다.
그런 용도로 NLTK는 기본 불용어 목록 179개를 제공합니다. 해당 불용어 목록은 stopwords.words('english')로 접근할 수 있습니다. 한번 확인해 볼게요.
stopwords.words('english')로 받아온 불용어들을 세트 자료형으로 저장해 주겠습니다.
from nltk.corpus import stopwords
nltk.download('stopwords')
stopwords_set = set(stopwords.words('english'))
print('불용어 개수 :', len(stopwords_set))
print(stopwords_set)
일반적인 코퍼스에서 많이 사용되지만 분석에 크게 활용되지 않는 단어들이 불용어 세트에 포함되어 있네요.
경우에 따라서는 NLTK에서 기본 제공하는 불용어에 새로운 단어를 추가하거나, 일부 단어를 기본 불용어 목록에서 제거해야 할 수도 있죠. 이런 경우에는 세트 데이터 형식의 add(), remove() 함수를 사용하면 됩니다. 한번 stopwords_set에 원하는 불용어를 추가하고 삭제해 볼게요.
stopwords_set.add('hello')
stopwords_set.remove('the')
stopwords_set.remove('me')
print('불용어 개수 :', len(stopwords_set))
print('불용어 출력 :',stopwords_set)
NLTK에서 받아온 불용어 세트에 hello가 추가되었고, the와 me가 제거되었습니다.
또, NLTK가 기본 제공하는 불용어가 아니라 새로운 불용어 세트를 정의해서 사용할 수도 있습니다.
my_stopwords_set = {'i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves'}
print(my_stopwords_set)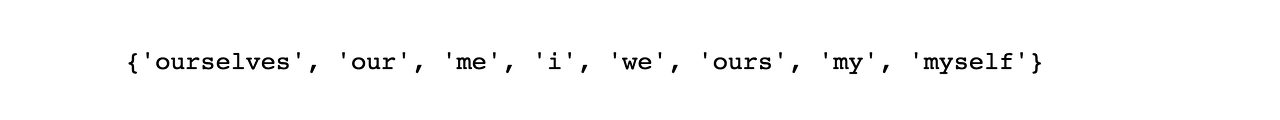
불용어(Stopwords) 제거하기
등장 빈도와 단어 길이 기준으로 정제했던 cleaned_by_freq_len에서 불용어도 제거해 보겠습니다. cleaned_by_freq_len에 있는 토큰을 하나씩 순회하면서 단어가 불용어 세트에 있는지 확인하고, 없을 때에만 cleaned_words에 저장해 줄게요.
stop_words_set = set(stopwords.words('english'))
# 불용어 제거
cleaned_words = []
for word in cleaned_by_freq_len:
if word not in stop_words_set:
cleaned_words.append(word)
불용어 제거 후 남은 토큰이 얼마나 있는지 확인해 볼게요.
# 불용어 제거 결과 확인
print('불용어 제거 전:', len(cleaned_by_freq_len))
print('불용어 제거 후:', len(cleaned_words))
102개의 불용어가 잘 제거됐습니다. 처음 코퍼스에서는 단어가 굉장히 많았는데, 정제 과정을 다 끝내고 나니 67개의 단어만 남았네요.
불용어 처리 함수 만들기
불용어 처리를 위한 코드도 함수로 만들어 두겠습니다. 함수 이름은 clean_by_stopwords()로 하고, 단어 토큰화 된 토큰 리스트와 불용어 세트를 파라미터로 받아 정제된 토큰 리스트를 반환하도록 함수를 만들어 볼게요.
preprocess.py
# 불용어 제거 함수
def clean_by_stopwords(tokenized_words, stop_words_set):
cleaned_words = []
for word in tokenized_words:
if word not in stop_words_set:
cleaned_words.append(word)
return cleaned_words
만든 함수는 preprocess.py 파일에 추가하고 이후 레슨에서 필요할 때마다 불러와서 사용하겠습니다.
'Data Analysis > Natural Language Processing(NLP)' 카테고리의 다른 글
| 자연어 전처리 적용 I (0) | 2023.06.08 |
|---|---|
| 불용어 제거 실습 (0) | 2023.06.08 |
| 정제 실습 (0) | 2023.06.06 |
| 정제(Cleaning) (2) | 2023.06.06 |
| 단어 토큰화 실습 (0) | 2023.06.06 |