
안녕하세용
다들 한 주 잘보내고 계신지요.
이번주는 머 비만 오다 끝나네요.
저는 어제 새벽에 배탈이나서 거의 잠을 못잔 상태인데요… 머리가 깨질 것 같슴다ㅜㅠ
하지만 오늘도 어디인지 모르는 저의 자리에서 SQL 공부 함 때리겠습니다.
자자 드디어 procedure을 끝내고 이제 index 로 넘어가보려합니다.
사실 지금 배우는 것은 거의 응애 걸음마 수준이고 이것을 자유자재로 쓸라하면 직접 실무에서 쿼리를 짜보고 그 쿼리로 사수한테 깨져가며(?) 배우는게 실력이 가장 빨리 느는 지름길입니다.
약간 마시면서 배우는 술게임 같은 느낌..?
그럼 오늘도 한번 드가봅시다
렛츠
기릿
테이블 안에 데이터가 몇 억개나 있는데 거기서 ‘나이’가 26인 사람을 찾고 싶다면 어쩔까요?
어쩌긴 멀 어째요!!
SELECT 머 WHERE 이런거 써서 쿼리 때리면 되겠죠?
근데 이 쿼리를 쏘게 된다면 컴퓨터는 몇 억개의 행을 하나씩 찾으면서 다 뒤집니다.(매우매우매우 느림)
만약 이렇게 하기 싫다? 그럼 index를 만들어둡니다.
업 다운 놀이
1 2 3 4 … 99 100
예를들어 책상에 1~100까지 써있는 카드를 쫙 펼쳐놨다고 해봅시다.
제가 지금 어떤 숫자를 머릿속에 상상하고 있는지 맞춰보십쇼.
저는 ‘Yes or No’만 말할 수 있습니다.
여기서 하수는
1임? ← no
그럼 2임? ← no
그럼 3? ← no
…
이런식으로 계속 물어보겠죠
하지만 고수는
50보다 큼? ← yes
그럼 75보다 작음? ← yes
그럼 68보다 큼? ← yes
…
이런식으로 반을 소거하면서 답이 아닌 것을 소거합니다.
그럼 훨씬 더 질문의 갯수가 적게 들겠죠.
그래서 DataBase에 있는 데이터도 이런식으로 소거하며 검색할 수 있습니다.
그럼 몇억개의 행이 있어도 몇십번 만의 질문으로 데이터를 찾을 수 있는데
이렇게 하려면 조건이 있습니다.
뭘까요?
맞습니다.
‘정렬’이 되어 있어야겠죠. 그래야지 절반씩 소거해도 원하는 값을 범위에서 찾을 수 있을테니까용
그래서 검색을 빠르게 만들기 위해 ‘따로 복사 후 정렬해둔 컬럼’을 index라고 합니다.
Binary Search Tree
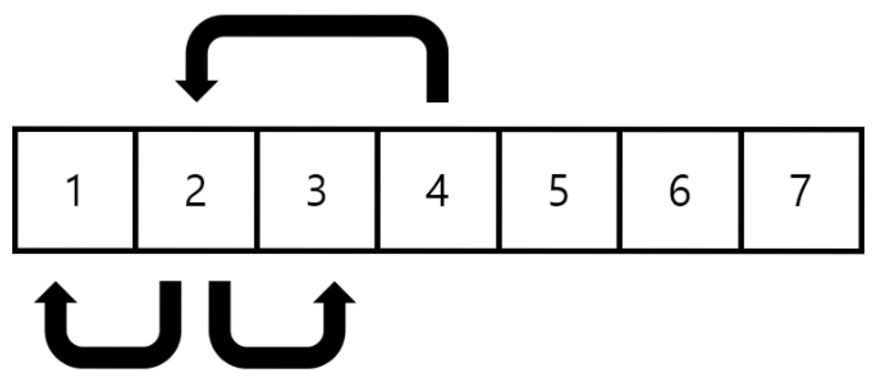
데이터를 빠르게 찾고 싶다면 데이터를 빠르게 정렬하면 된다고 했습니다.
숫자 뿐만 아니라 문자도 마찬가지입니다.
그럼 아까처럼 절반씩 소거하며 검색할 수 있습니다.
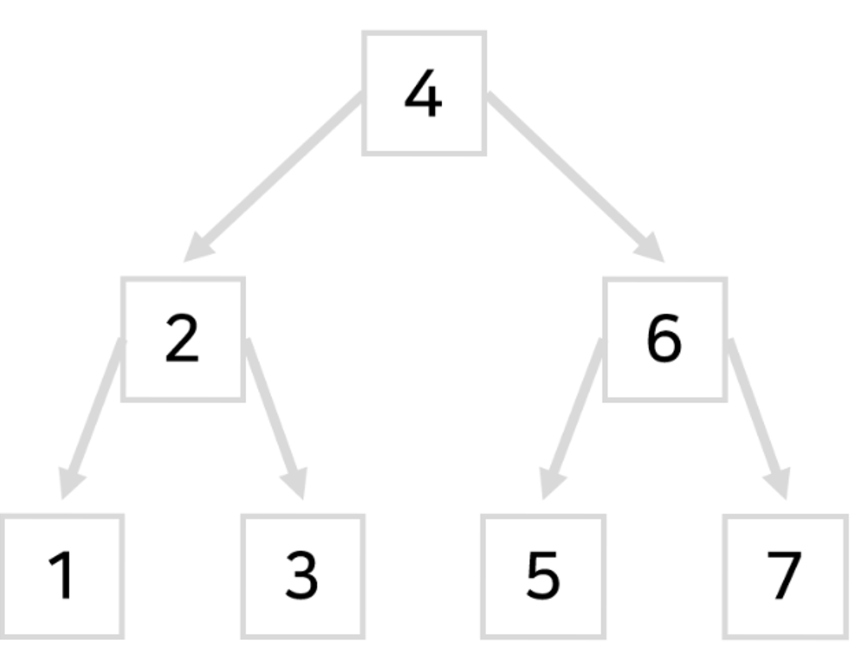
⬆️ 사실 굳이 물리적으로 일렬 정렬 안해도
- 트리같이 숫자를 왼쪽→오른쪽 으로 123 순으로 배치만 잘하고
- 서로 화살표로 이어두어도
아까처럼 반씩 소거하며 빠르게 검색이 가능합니다.
??? : 그래서 다알겠는데 왜 이름이 Binary Search 냐고요??
트리를 뒤집어 놓은 나무 같다고 해서 있어보이게 Binary Search Tree라고 부릅니다.
그래서 데이터 들을 binary tree 형태로 미리 놓아야지 빠르게 찾을 수 있다고 해도 똑같은거죠.(실제로 index도 tree 형태로 배치해두는 경우가 많습니다.)
B-tree(비 트리)
여러분 먼가 조금만 더 욕심 내고 싶지 않으십니까??
50%말고 머 65%, 75% 씩 소거해보고 이런식으로도 할 수 있지않을까요?
불가능합니다.
는 구라고 B-tree 형태로 자료를 배치해두면 쌉가넝합니다.
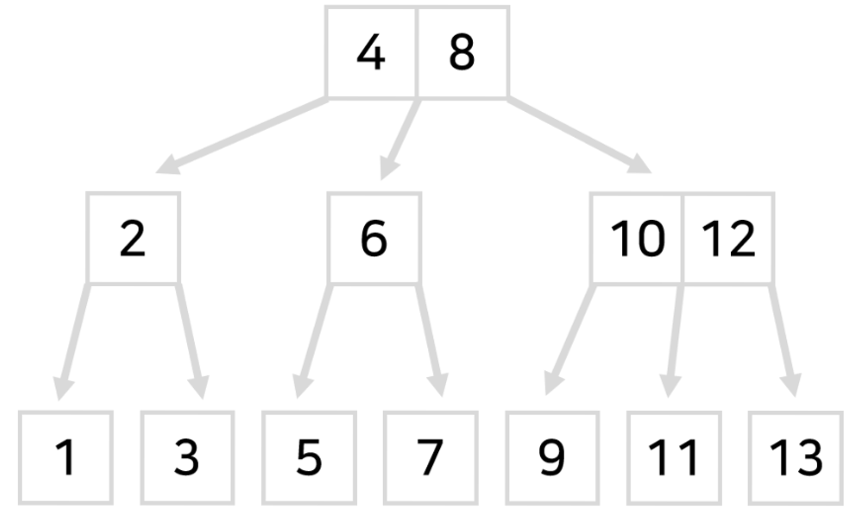
- 하나의 칸에 숫자를 여러개씩 담아 놓는 식으로 배치하고
- 갈림길을 세개 이상씩 쪼개놓습니다.
이런 x친 짓을 B-tree라고 합니다…
아까와 비교해볼까요?
아까는 2번의 화살표 이동으로 1~7까지 찾을 수 있었는데요.
지금은 2번의 화살표 이동으로 1~13까지는 충분히 찾을 수 있을 것같네요.
B+tree(비 플러스 트리)
1절 2절 뇌절까지해서 B+tree란 것을 컴터 과학자들이 발명합니다;;
B+tree라고 해서 데이터를 트리 중간중간에 보관하는것이 아닌
가장 밑에만 보관합니다.
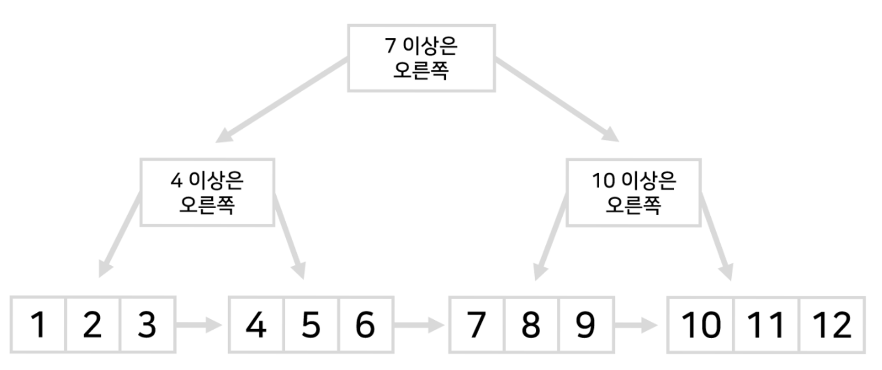
⬆️ B+tree는 B-tree와 정렬 방식이 똑같지만 데이터를 맨 아래만 저장해둡니다.
가장 밑부분은 테이블을 일정한 크기로 쪼개고 정렬해서 저장해줍니다.
그리고 데이터 탐색 가이드라인 만 윗부분으로 저장합니다.
이렇게 해두면 아까랑 똑같이 두세번만에 데이터를 찾을 수 있는데요.
더 나은 점은요.
범위를 찾을때 유리합니다. ‘나이가 2와 5사이인 숫자를 다 찾아주세염~~’ 같은 검색을 할때 말이죠.
그래서 관계형 DB들은 보통 일반적으로 B+Tree로 index를 정렬해둡니다.
물론 B+Tree 안쓰는 DB들도 있습니다.
결론
자 그래서 결론이 머냐?
원하는 데이터를 빠르게 찾기 위해서
컬럼을 잘라내서 tree형태로 정렬해둔 것
이것을 전문용어로 index라고 합니다.
자 컴퓨터가 한번 로직을 어떻게 활용하는지 봅시다.
저희가 ‘WHERE age = 26’이라는 쿼리를 땅!하고 치면
- 컴퓨터는 index안에서 age = 26인 행을 빠르게 찾습니다.
- 그담에 age = 26인 index의 행과 연결된 원래 테이블의 행을 찾아와 결과로 출력합니다.
머 이런 과정으로 인해 검색속도가 빨라지는 것입니다.
=, <, >, ≤, ≥, BETWEEN, LIKE 연산자를 사용할때 index가 사용됩니다.
LIKE를 사용할 시에 시작이 %기호가 아닐 때만 (긍까 LIKE ~% 일때만) index를 사용해주는 것입니다.
하지만 index는 차갑다.
하지만 index는 매번 자동으로 생성되주진 않습니다.
여러분이 ‘이컬럼의 index를 만들어주세욤’이라고 요구해야 index 생성이 가능합니다.
왜그러냐구요?
저도모름ㅋ
은 아니고 매번 index를 생성해주면 불필요한 프로세스가 발생하고 오히려 성능저하가 일어날 수 있기때문에 index는 항상 필요하지 않습니다.
자동으로 index가 적용되는 컬럼이 있다!?!?
PK(Primary Key) 컬럼은 따로 index를 만들 필요가 없습니다.
왜냐면 테이블에 pk가 있으면 애초에 pk기준으로 정렬해서 보관해주기 때문이죠
그래서 그냥 index가 디폴트로 생성되어 있슴다.
그래서 pk 검색시에는 별거 안해놔도 매우빠르게 찾아주는 이유가 index가 자동으로 생성되어 있기 때문입니다.
pk가 아닌 일반 컬럼들은 검색속도를 향상시키고 싶다? 하면 index를 만들어줍니다.
index의 단점
index라고 꼭 장점만 있는 것은 아닙니다.
테이블 컬럼마다 index 만들어두면 select 를 매우빠르게 처리할 수 있다했자나요.
- index는 만들때마다 추가 하드용량을 차지합니다.(컬럼 한두개 복사하는 수준이라 크게 문제는 안됨)
- index가 있는 테이블은 나중에 삽입, 수정, 삭제… 데이터를 조작할때 내부적으로 추가연산이 필요해 느려질 수 있습니다.
왜냐면 테이블과 index에 각각 데이터를 반영해야하니까요.
근데 오히려 데이터가 많으면 삽입, 수정, 삭제 시에도 원하는 행을 매우빨리 찾을 수 있어서 크게보면 단점은 아니죠.
그래서 우리가 만약 자주 찾는 컬럼이 있으면 index를 만들어두는 습관을 들입시다.
'DI(Digital Innovation) > DataBase & SQL 뽀개기' 카테고리의 다른 글
| 진짜 검색기록은 최종보스 Full Text Search (0) | 2024.04.02 |
|---|---|
| index 만들어보기 그리고 성능 평가해보기 (0) | 2024.04.01 |
| procedure, function 안에서 쓸 수 있는 IF문법 (0) | 2024.03.28 |
| procedure 많이 만들기 싫다면? 파라미터로 해결하세요~ (0) | 2024.03.28 |
| procedure에서 많이 쓰는 변수 문법 (0) | 2024.03.28 |
안녕하세용
다들 한 주 잘보내고 계신지요.
이번주는 머 비만 오다 끝나네요.
저는 어제 새벽에 배탈이나서 거의 잠을 못잔 상태인데요… 머리가 깨질 것 같슴다ㅜㅠ
하지만 오늘도 어디인지 모르는 저의 자리에서 SQL 공부 함 때리겠습니다.
자자 드디어 procedure을 끝내고 이제 index 로 넘어가보려합니다.
사실 지금 배우는 것은 거의 응애 걸음마 수준이고 이것을 자유자재로 쓸라하면 직접 실무에서 쿼리를 짜보고 그 쿼리로 사수한테 깨져가며(?) 배우는게 실력이 가장 빨리 느는 지름길입니다.
약간 마시면서 배우는 술게임 같은 느낌..?
그럼 오늘도 한번 드가봅시다
렛츠
기릿
테이블 안에 데이터가 몇 억개나 있는데 거기서 ‘나이’가 26인 사람을 찾고 싶다면 어쩔까요?
어쩌긴 멀 어째요!!
SELECT 머 WHERE 이런거 써서 쿼리 때리면 되겠죠?
근데 이 쿼리를 쏘게 된다면 컴퓨터는 몇 억개의 행을 하나씩 찾으면서 다 뒤집니다.(매우매우매우 느림)
만약 이렇게 하기 싫다? 그럼 index를 만들어둡니다.
업 다운 놀이
1 2 3 4 … 99 100
예를들어 책상에 1~100까지 써있는 카드를 쫙 펼쳐놨다고 해봅시다.
제가 지금 어떤 숫자를 머릿속에 상상하고 있는지 맞춰보십쇼.
저는 ‘Yes or No’만 말할 수 있습니다.
여기서 하수는
1임? ← no
그럼 2임? ← no
그럼 3? ← no
…
이런식으로 계속 물어보겠죠
하지만 고수는
50보다 큼? ← yes
그럼 75보다 작음? ← yes
그럼 68보다 큼? ← yes
…
이런식으로 반을 소거하면서 답이 아닌 것을 소거합니다.
그럼 훨씬 더 질문의 갯수가 적게 들겠죠.
그래서 DataBase에 있는 데이터도 이런식으로 소거하며 검색할 수 있습니다.
그럼 몇억개의 행이 있어도 몇십번 만의 질문으로 데이터를 찾을 수 있는데
이렇게 하려면 조건이 있습니다.
뭘까요?
맞습니다.
‘정렬’이 되어 있어야겠죠. 그래야지 절반씩 소거해도 원하는 값을 범위에서 찾을 수 있을테니까용
그래서 검색을 빠르게 만들기 위해 ‘따로 복사 후 정렬해둔 컬럼’을 index라고 합니다.
Binary Search Tree
데이터를 빠르게 찾고 싶다면 데이터를 빠르게 정렬하면 된다고 했습니다.
숫자 뿐만 아니라 문자도 마찬가지입니다.
그럼 아까처럼 절반씩 소거하며 검색할 수 있습니다.
⬆️ 사실 굳이 물리적으로 일렬 정렬 안해도
- 트리같이 숫자를 왼쪽→오른쪽 으로 123 순으로 배치만 잘하고
- 서로 화살표로 이어두어도
아까처럼 반씩 소거하며 빠르게 검색이 가능합니다.
??? : 그래서 다알겠는데 왜 이름이 Binary Search 냐고요??
트리를 뒤집어 놓은 나무 같다고 해서 있어보이게 Binary Search Tree라고 부릅니다.
그래서 데이터 들을 binary tree 형태로 미리 놓아야지 빠르게 찾을 수 있다고 해도 똑같은거죠.(실제로 index도 tree 형태로 배치해두는 경우가 많습니다.)
B-tree(비 트리)
여러분 먼가 조금만 더 욕심 내고 싶지 않으십니까??
50%말고 머 65%, 75% 씩 소거해보고 이런식으로도 할 수 있지않을까요?
불가능합니다.
는 구라고 B-tree 형태로 자료를 배치해두면 쌉가넝합니다.
- 하나의 칸에 숫자를 여러개씩 담아 놓는 식으로 배치하고
- 갈림길을 세개 이상씩 쪼개놓습니다.
이런 x친 짓을 B-tree라고 합니다…
아까와 비교해볼까요?
아까는 2번의 화살표 이동으로 1~7까지 찾을 수 있었는데요.
지금은 2번의 화살표 이동으로 1~13까지는 충분히 찾을 수 있을 것같네요.
B+tree(비 플러스 트리)
1절 2절 뇌절까지해서 B+tree란 것을 컴터 과학자들이 발명합니다;;
B+tree라고 해서 데이터를 트리 중간중간에 보관하는것이 아닌
가장 밑에만 보관합니다.
⬆️ B+tree는 B-tree와 정렬 방식이 똑같지만 데이터를 맨 아래만 저장해둡니다.
가장 밑부분은 테이블을 일정한 크기로 쪼개고 정렬해서 저장해줍니다.
그리고 데이터 탐색 가이드라인 만 윗부분으로 저장합니다.
이렇게 해두면 아까랑 똑같이 두세번만에 데이터를 찾을 수 있는데요.
더 나은 점은요.
범위를 찾을때 유리합니다. ‘나이가 2와 5사이인 숫자를 다 찾아주세염~~’ 같은 검색을 할때 말이죠.
그래서 관계형 DB들은 보통 일반적으로 B+Tree로 index를 정렬해둡니다.
물론 B+Tree 안쓰는 DB들도 있습니다.
결론
자 그래서 결론이 머냐?
원하는 데이터를 빠르게 찾기 위해서
컬럼을 잘라내서 tree형태로 정렬해둔 것
이것을 전문용어로 index라고 합니다.
자 컴퓨터가 한번 로직을 어떻게 활용하는지 봅시다.
저희가 ‘WHERE age = 26’이라는 쿼리를 땅!하고 치면
- 컴퓨터는 index안에서 age = 26인 행을 빠르게 찾습니다.
- 그담에 age = 26인 index의 행과 연결된 원래 테이블의 행을 찾아와 결과로 출력합니다.
머 이런 과정으로 인해 검색속도가 빨라지는 것입니다.
=, <, >, ≤, ≥, BETWEEN, LIKE 연산자를 사용할때 index가 사용됩니다.
LIKE를 사용할 시에 시작이 %기호가 아닐 때만 (긍까 LIKE ~% 일때만) index를 사용해주는 것입니다.
하지만 index는 차갑다.
하지만 index는 매번 자동으로 생성되주진 않습니다.
여러분이 ‘이컬럼의 index를 만들어주세욤’이라고 요구해야 index 생성이 가능합니다.
왜그러냐구요?
저도모름ㅋ
은 아니고 매번 index를 생성해주면 불필요한 프로세스가 발생하고 오히려 성능저하가 일어날 수 있기때문에 index는 항상 필요하지 않습니다.
자동으로 index가 적용되는 컬럼이 있다!?!?
PK(Primary Key) 컬럼은 따로 index를 만들 필요가 없습니다.
왜냐면 테이블에 pk가 있으면 애초에 pk기준으로 정렬해서 보관해주기 때문이죠
그래서 그냥 index가 디폴트로 생성되어 있슴다.
그래서 pk 검색시에는 별거 안해놔도 매우빠르게 찾아주는 이유가 index가 자동으로 생성되어 있기 때문입니다.
pk가 아닌 일반 컬럼들은 검색속도를 향상시키고 싶다? 하면 index를 만들어줍니다.
index의 단점
index라고 꼭 장점만 있는 것은 아닙니다.
테이블 컬럼마다 index 만들어두면 select 를 매우빠르게 처리할 수 있다했자나요.
- index는 만들때마다 추가 하드용량을 차지합니다.(컬럼 한두개 복사하는 수준이라 크게 문제는 안됨)
- index가 있는 테이블은 나중에 삽입, 수정, 삭제… 데이터를 조작할때 내부적으로 추가연산이 필요해 느려질 수 있습니다.
왜냐면 테이블과 index에 각각 데이터를 반영해야하니까요.
근데 오히려 데이터가 많으면 삽입, 수정, 삭제 시에도 원하는 행을 매우빨리 찾을 수 있어서 크게보면 단점은 아니죠.
그래서 우리가 만약 자주 찾는 컬럼이 있으면 index를 만들어두는 습관을 들입시다.
'DI(Digital Innovation) > DataBase & SQL 뽀개기' 카테고리의 다른 글
| 진짜 검색기록은 최종보스 Full Text Search (0) | 2024.04.02 |
|---|---|
| index 만들어보기 그리고 성능 평가해보기 (0) | 2024.04.01 |
| procedure, function 안에서 쓸 수 있는 IF문법 (0) | 2024.03.28 |
| procedure 많이 만들기 싫다면? 파라미터로 해결하세요~ (0) | 2024.03.28 |
| procedure에서 많이 쓰는 변수 문법 (0) | 2024.03.28 |