
만약 여러분이 게시판 서비스 같은것을 운영한다고 해봅시다.
그래서 테이블 하나당 게시물 내용, 작성자, 발행일을 저장하는데 검색기능이 필요해진겁니다.
검색기능은 어떻게 구현할까요?
LIKE 연산자
한 몇달전에 배웠쥬? 간단한 검색기능을 만들고 싶다면 컬럼명 LIKE %단어% 하면 됩니다.
짧은 문장은 이걸로 커버가 가능하지만 몇가지 단점이 있습니다.
- % 기호를 맨앞에 쓰면 인덱스 활용을 못하고
- 문장이 좀 길거나 행이 너무 많아지면 LIKE 연산자의 속도가 매우 느립니다.
그래서 이걸 보완하기위해 full text index란 것이 있습니다.
Full text search를 위한 index
긴 글도 DB 컬럼하나에 보관할 수 있습니다.
text 데이터 타입을 쓴다면 최대 6만5천자를 보관할 수 있는데용
이렇게 긴 글안에서 원하는 text를 찾고싶다면 당연히 index를 만들어야 검색이 빨라지겠죠?
근데 이런 긴글은 그냥 index 말고 full text search index를 만들어두면 됩니다.
굳이 궁금하실까봐 어떤 원리로 index를 만들어주는지 함 보겠습니다ㅎㅎ
| id | 글 |
| 1 | I run regulary. |
| 2 | I eat breakfast. |
| 3 | I like running. |
| 4 | I like eating chicken |
| 5 | I swim in the sea |
⬆️ 이런 테이블이 있습니다.
이 테이블에 full text index를 만들라고 시킨다면
| 단어 | 어떤 행에 나오냐면 |
| eat | 2, 4 |
| run | 1, 3 |
| swim | 5 |
⬆️ 긴 글에 있는 모든 단어를 뽑아서 정렬하고
그 단어가 어디서 출몰하고 있는지 옆에 적어둡니다.
이러면 run 이런 단어를 검색했을때 어떤 행에 있는지 빠르게 파악할 수 있겠죠??
이게 끝입니다.
근데 문장안에서 stopwords라고 부르는
‘is the a are and I’등 내용과 상관없는 쓸데없는 단어들을 제거하고 index를 만드는 경우가 있습니다.
그래서 웹의 검색엔진들이 is the a are 이런 내용 붙여서 검색하면 대부분 무시하는 비밀이 바로 이겁니다! 신기하죠 ㅎㅎ
Full text index 만드는 법
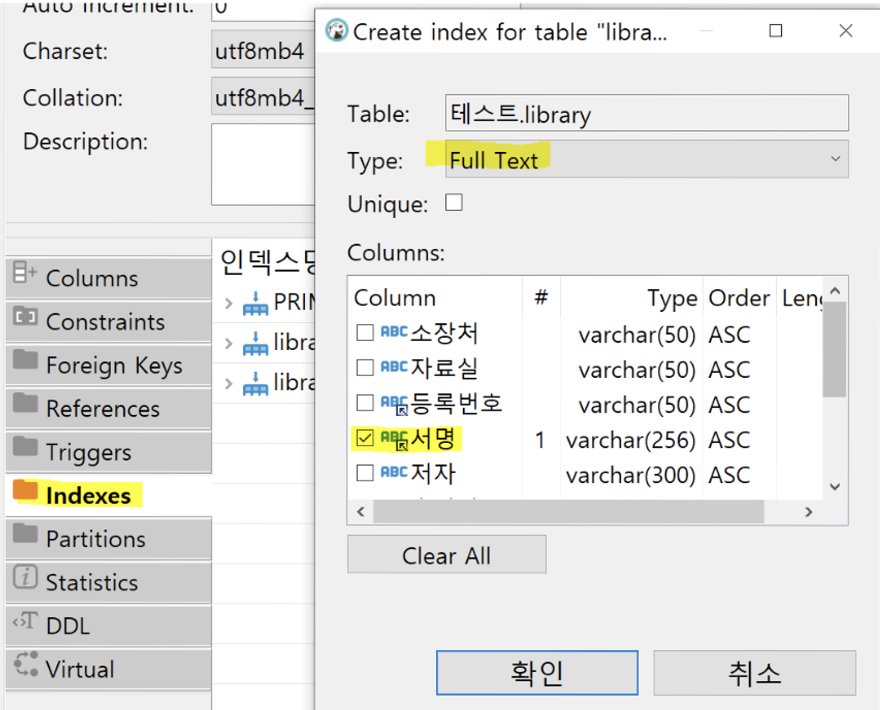
⬆️ 자 어제 본 library 테이블입니다. 어떤 컬럼에 full text index를 생성하고 싶다면
저번시간에 했던 index만드는 거랑 똑같은데 걍 Btree 말고 full text 선택하면 됩니다.
CREATE FULLTEXT INDEX 인덱스이름작명 ON 테이블명(컬럼명);
쿼리로는 이렇게 작성하면 됩니다.
Full text index를 이용해 검색하려면?
이건 좀 특별한 문법을 쓰는데요.
MATCH() AGAINST() 이런게 필요합니다.
WHERE 뒤에 조건식 형태로도 넣을 수 있고 이거쓰면 full text index해서 매우빠르게 행을 찾아줍니다.
SELECT * FROM library WHERE MATCH(서명) AGAINST('부동산');
이렇게 쿼리를 때리면 ‘부동산’이라는 정확한 단어를 가진 행을 누구보다 빠르게 남들과는 다르게 행을 찾아줍니다.
진짜 빠른지 확인하려면 어제 배운 execution plan을 확인합니다.
뽀인트 🎁
뽀인트 1
사실 그냥 MATCH() AGINST() 사용하면 IN NATURAL LANGUAGE MODE 라는 모드로 검색해주는데
영어의 경우 IN NATURAL LANGUAGE MODE 쓰면 검색어에 a, is, the, are, or 이런 stopwords가 포함되어 있을경우 무시하고 검색해줍니다.(* 한글은 그냥 그런거 적용안해줍니다.)
뽀인트 2
AGAINST(’부동산’) 이라고 검색하면 정확히 ‘부동산’ 단어만 찾아줍니다. 당연히 ‘부동산이 갑자기’이런거 못찾음.
그래서 보통은 이거 말고 더 다양한 기능을 하는 IN BOOLEAN MODE를 사용합니다.
SELECT * FROM library WHERE MATCH(서명) AGAINST('부동산' IN BOOLEAN MODE);
IN BOOLEAN MODE 를 이렇게 킬 수 있습니다.
근데 키기만 하면 아까꺼랑 그냥 똑같음ㅅㄱ
SELECT * FROM library WHERE MATCH(서명) AGAINST('부동산*' IN BOOLEAN MODE);
키워드 뒤에 * 기호를 이용해야합니다.
여기서 * 는 % ← 이거랑 유사하게 작동합니다.
위 코드는 부동산이 앞에 포함된 모든 단어를 검색해줍니다.(부동산이, 부동산을… 이런거)
SELECT * FROM library WHERE MATCH(서명) AGAINST('부동산 종이접기' IN BOOLEAN MODE);
여러 단어를 넣으면 OR 연산을 해주는데요.
자동으로 부동산 or 종이접기가 포함된 결과를 출력합니다.(참고로 2자이하는 검색이 안됩니다.)
SELECT * FROM library WHERE MATCH(서명) AGAINST('+부동산 +빅데이터' IN BOOLEAN MODE);
+ 기호를 앞에 붙이면 해당 단어가 꼭 들어간 것만 찾아줍니다.
위처럼 쿼리날리면 ‘부동산’과 ‘빅데이터’가 꼭 들어간 걸 찾아줍니다.
대충 AND라고 보시면됩니다.
SELECT * FROM library WHERE MATCH(서명) AGAINST('-부동산 +빅데이터' IN BOOLEAN MODE);
- 는 앞에 붙이면 이 단어 걸러라는 뜻입니다.
위 쿼리는 ‘부동산’은 안들어있고 ‘빅데이터’는 들어있는 걸 찾아줍니다.
대충 NOT이라고 보시면 됩니다.
이 정도만 알아도 기본적인 웹서비스의 게시판 검색기능 정도는 오케이입니다.
지구 끝까지 찾아내고 싶다면 n-gram parser로 index 만들기
영어는 띄어쓰기 단위로 단어를 분리할 수 있습니다.
하지만 자랑스런 한글, 일본어, 중국어 이거는 별로 띄어쓰기가 중요하지 않습니다.
그래서 글자들을 그냥 다 붙여쓴 담에 몇글자단위로 잘라서 index를 생성하는 방식이 있는데 이걸 ‘n-gram parser’라고 합니다.
예를들어 ‘삼성 투자’라는 문자를 n-gram으로 index를 생성하면
| 단어 | 어떤행에 있냐면 |
| 삼성 | (생략) |
| 성투 | (생략) |
| 투자 | (생략) |
띄어쓰기를 무시하고 2자 단위로 잘라 index를 만들어줍니다.
(최소 글자는 항상 2자일필요 없고 맘대로 설정가능)
그럼 이전과는 다르게 다양한 단어도 지구끝까지 찾아낼 수 있는 장점이 있습니다.
CREATE FULLTEXT INDEX 인덱스이름작명 ON 테이블명(컬럼명) WITH PARSER ngram;
n-gram parser는 무조건 index를 쿼리로 작성해야하는데요.
저는 아까 ‘서명’에 있던 index 삭제하고 이걸로 다시만들어봤습니다.
SELECT * FROM library
WHERE MATCH(서명) AGAINST('철학을');
그래서 n-gram 을 이용해서 index를 만들어둔후
위처럼 검색하면 ‘철학’, ‘학을’ 이 포함된 모든 책제목을 찾아주겠지요.
그래서 ‘종이학을 접어보자’ 이런 책이름도 검색되는 것입니다.
왜냐면 IN NATURAL LANGUAGE MODE + ngram parser index를 적용하면 검색어를 2개단위로 잘라서 하나라도 일치하면 다뽑아내줘서 그렇습니다.
그래서 지엽적인 책 제목까지 지구끝까지 긁어모은다는 장점도 있는데요.
- 일단 n-gram parser로 index를 만들면 하드 용량을 많이 차지할 수 있고
- 쓸데 없는 결과도 많이 출력되는 단점도 있습니다.
근데 잘 보시면 기본적인 관련도가 높은걸 위에 올려두는 게 있죠
나름 네카라쿠배의 머리인 ‘네이버’같은 검색엔진을 조금이라도 흉내낼 수 있는 기능이라고 보면 됩니다.
참고로 MATCH(서명) AGAIN(’철학을’) 이걸 컬럼명 쓰는 자리에 넣어버리면 관련도 점수도 출력가능합니다.
- 이정도의 성능으로 성에 안찬다면 네이버, 구글, 카카오, 배민 처럼 검색성능이 아주 중요한 사이트를 만들고 있다면
’elastic search’ 라든지 검색만을 위한 DB 또는 서비스를 따로 사용할 수 있기 때문에 그걸 쓰는게 나을 수도 있습니다.
- 다른 DBMS는 다른 문법이나 방법을 사용하는 경우가 많아 필요시 따로 검색해서 사용 ㄱㄱ
'DI(Digital Innovation) > DataBase & SQL 뽀개기' 카테고리의 다른 글
| index 만들어보기 그리고 성능 평가해보기 (0) | 2024.04.01 |
|---|---|
| 솔로지옥 덱스말고 SQL index (0) | 2024.03.28 |
| procedure, function 안에서 쓸 수 있는 IF문법 (0) | 2024.03.28 |
| procedure 많이 만들기 싫다면? 파라미터로 해결하세요~ (0) | 2024.03.28 |
| procedure에서 많이 쓰는 변수 문법 (0) | 2024.03.28 |