
저희가 지난 시간 까지 index를 만들어 놓으면 성능이 향상된다고 배웠습니다.
SELECT 가 얼마나 성능이 향상되었는지 확인해볼까요??
execution plan(실행 계획) 분석해보기
library.csv 파일을 가져와보겠습니다.
이 csv 파일은 6만건의 도서관 소장도서 정보가 저장되어있는 데이터셋입니다.
SELECT * FROM library WHERE 등록번호 = 'CEM97499'
근데 이게 생각보다 오래 걸리는 것 같습니다.
뭔가가 오래 걸리는 것 같으면 실행계획부터 분석하고 봐도 되는데요
원하는 SELECT 쿼리문에 커서 올리고 DBever 상단메뉴 SQL 편집기 → 실행계획보기를 누르면 실행계획이 출력됩니다.
이게 컴퓨터가 이 쿼리문을 어케 실행할지 계획을 보여주는건데요.
이걸보고 성능평가 같은것을 확인할 수 있습니다.
→ 이게 아니여도 SELECT 쿼리 왼쪽에 EXPLAIN 키워드 붙이고 실행해도 비슷합니다.
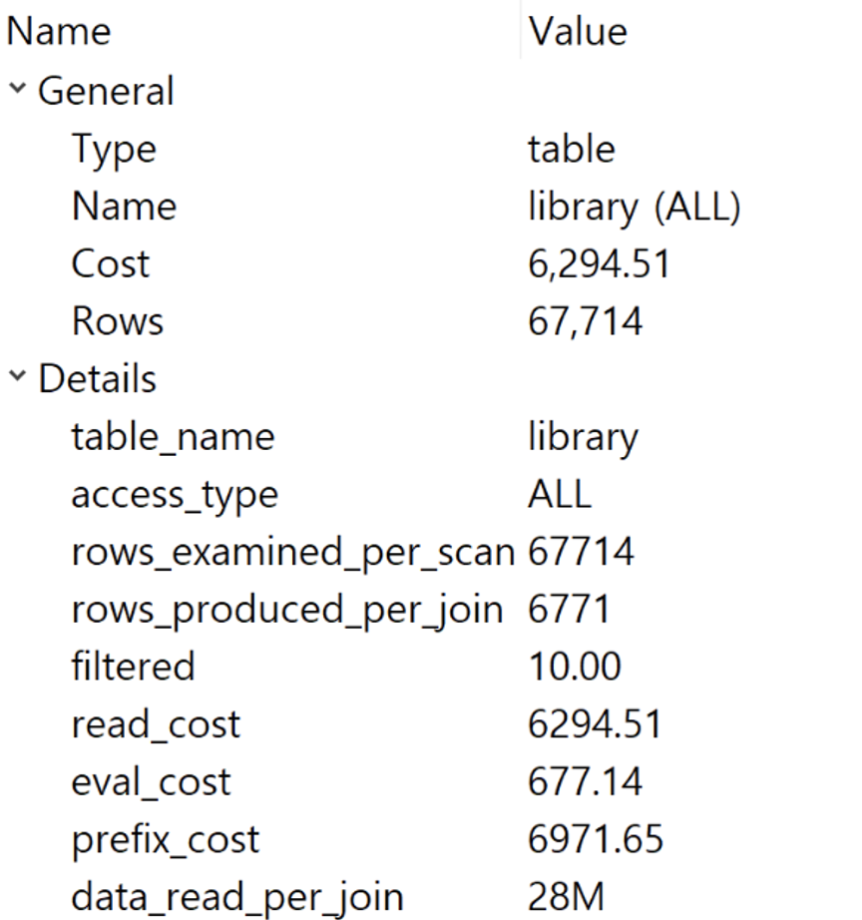
이런 것이 뜨는데용
cost 는 어림잡아 걸리는 시간이라고 생각하시면 됩니다. 낮으면 좋겠죠?
저희는 보통 몇천, 몇만 정도면 1초에 몇백건 실행해도 부담이 되진 않습니다. 근데 거의 10만 넘어가면서 부터는 많이 실행하면 컴퓨터의 부담을 주거나 병목현상이 일어날 수 있습니다.
그래서 이 경우엔 index를 통해 개선하는 것이 좋습니다.
access_type 혹은 type 은 ALL 만 피하시면 됩니다.
ALL이 무슨의미냐면 ALL이 기록되어 있으면 테이블 전체 행을 full scan한다는 소리여서 성능이 매우 낮아집니다.
ALL만 안나오면 됩니다.
보통 여기는 index, range, ref, const 이런것들이 들어가면 됩니다.
filtered 는 컴퓨터가 읽은 행을 출력결과에 넣는 비율인데
예를 들어 10개의 행을 읽었는데 1개의 행만 출력 결과에 나오게 하고싶으면 10%로 게산됩니다.
그래서 100%에 가까울수록 좋은데 수치가 정확한 건 아니라, 보조지표 정도로 보시면 될 것 같습니다.
나머지는 execution plan 읽는 법 참조해서 보십쇼
테이블에 index 생성하려면
그래서 만약 cost 가 너무 높아서 index를 만드려고 합니다.
이건 쉽습니다.
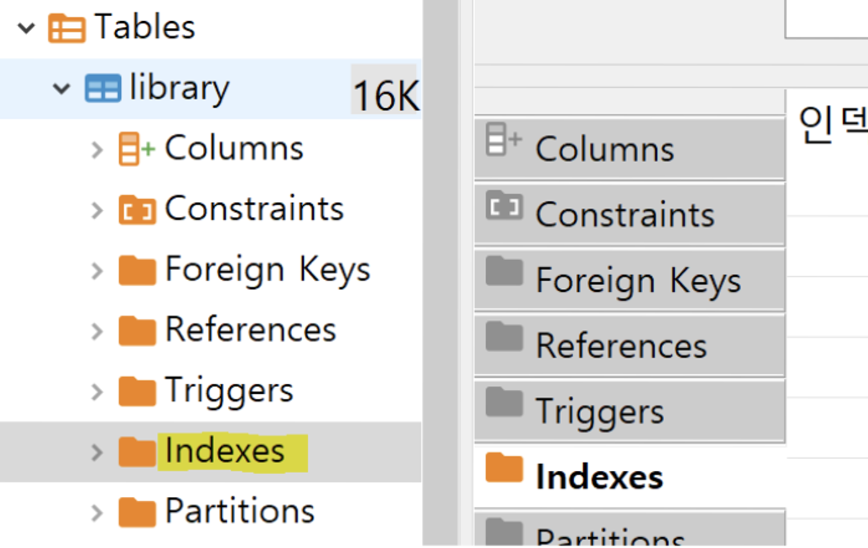
⬆️ 사실 DBeaver에서 indexes 메뉴를 지원해줍니다 ㅋ
거기서 우클릭 해 index 하나 씩 생성ㄱㄱ
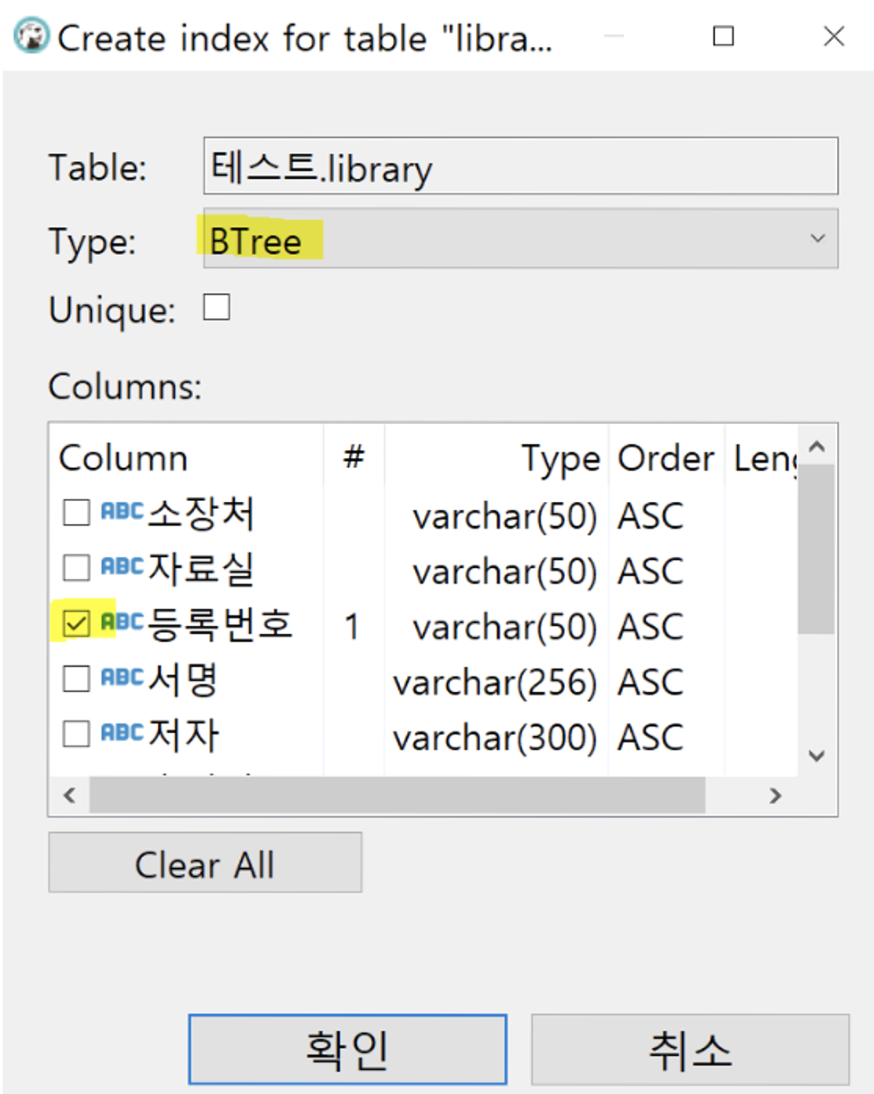
⬆️ 그럼 창이 하나 뜨는데 원하는 컬럼하나 선택해서 확인누르고 저장 하면 끝입니다. 쉽쥬??
- 참고로 Btree(B+tree) 말고 다른 식으로 index 만들 수 있는데
Rtree는 2차원 좌표값을 저장한 컬럼일 때 사용가능합니다.(위도,경도)
Full text는 긴 문장에서 원하는 단어 빠르게 찾고 싶을때 씁니다.(글 검색 기능을 만들때 주로 사용) - UNIQUE 제약을 줘도 상관없는, 행마다 서로 다른 값을 가진 컬럼이라면 Unique를 체크해서 만들어두면 검색성능이 더빨라집니다. 이런걸 Unique index라고 합니다.
index 만든 후 성능을 다시 평가해보자구
SELECT * FROM library WHERE 등록번호 = 'CEM97499'
등록 번호 컬럼에 index 만들었으니 위 쿼리를 다시 실행 해보겠습니다.
그리고 커서 찍고 ‘실행계획보기’누르겠습니다.

[틀린그림찾기 - 키썸]
다들 하셨나요? 아까는 cost가 6천을 넘었는데 1로 감소했네요. access_type도 ALL에서 ref 로 변경되었네요..
그럼 이쯤에서 똑똑한 친구들은 질문이 있겠죠
??? : 전에 말한 것처럼 범위를 지정하면 더 빠르다면서 왜 WHERE 등록번호 < ‘CEM97499’ 같은 index 안쓰나요?
예리한 질문입니다.
현재 테이블의 전체 행은 거의 6만개입니다. 근데 이 쿼리를 출력하면 거의 3만개의 행이 출현합니다.
원래 범위 검색시 출력할 행들이 많아서 출력할 행이 전체 행의 20%를 넘게된다면 index를 굳이 안써도 된다고 DBMS 혼자 북치고 장구치고 판단하여 걍 index 안씁니다.
강제로 쓰라고 명령할수도 있는데요. 이건 알아서 판단하게 냅둡시다.
PRIMARY KEY인 경우
ALTER TABLE library ADD COLUMN id int PRIMARY KEY AUTO_INCREMENT;
libary 테이블에 id라는 pk를 만들어 봅시다.
그리고 id = 어쩌구 저쩌구 컬럼을 찾으라고 쿼리를 짜겠습니다.
이건 어케 나올까요?
직접 해보십쇼.
해보셨나요?
access_type이 const 이런식으로 나올텐데요
NOT NULL + PRIMARY KEY 역할을 하는 컬럼은 = 등호로 검색 시 const가 뜹니다. 빠르고 좋단 뜻
그래서 pk 컬럼은 기본적으로 검색이 매우 빠르기 때문에 index 신경쓸 필요 없습니다.
다중 컬럼 index
SELECT * FROM 아무개 WHERE name = 'park' AND age = 20
위 쿼리 처럼 에를 들어 컬럼 2개 이상에서 검색 작업을 수행할때는
그 컬럼들 각각 index를 만드는 것보다
필요한 컬럼들을 전부 묶어서 index를 만들어두면 성능이 더 향상됩니다.
index 만들 때 여러개의 컬럼도 선택 가능합니다.
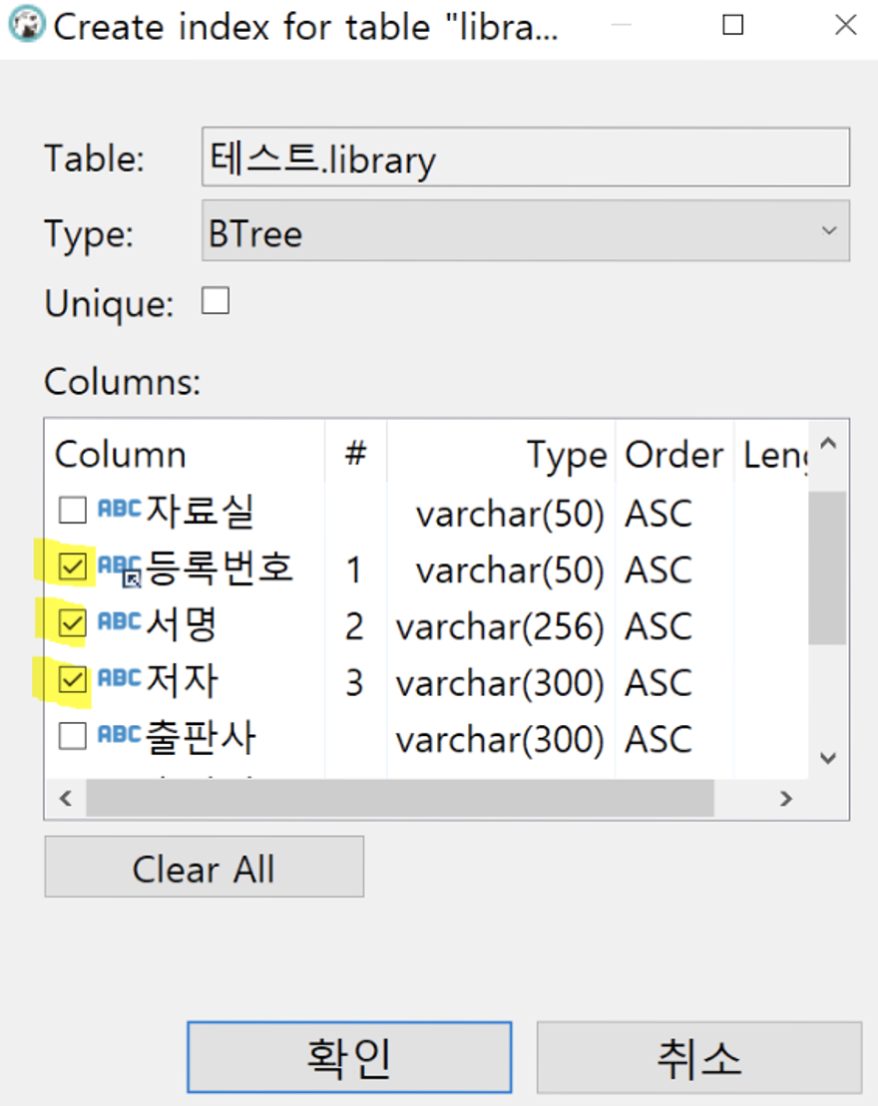
⬆️ 별거 없습니다. 걍 여러개 체크하면 됨
체크한 순서대로 묶어서 index를 만듭니다.
이렇게 해두면 뭐가 좋냐?
예를 들어 님들이 a, b, c 컬럼이 있는데
이걸 (a, b, c) 이렇게 묶어서 index를 만들어뒀다면
a, b, c 컬럼 전부에 조건 걸어주는 쿼리를 짤때 컴퓨터가 알아서 사용한단 뜻입니다.
a, b, c 각각 index를 만드는 것보다 다중컬럼 index가 더빨라서 한꺼번에 씁시다.
예를들어 (name, age) 순으로 다중컬럼 index를 만들어 놓았더라면
WHERE name = ? AND age = ?
이런 쿼리를 작성할 때 그 (name, age) index를 사용해줍니다.
name, age를 각각 index 만드는 것보다 쿼리속도가 더 빠를 수 있음
WHERE name = ?
실은 이런 쿼리에도 그 (name, age) index를 사용해줍니다.
WHERE age = ??
근데 이건 (name, age) 이걸 사용할 수 없어요...
왜냐?
다중 컬럼 순서가 name 이 먼저기 때문에…
그래서 다중컬럼 index는 컬럼 넣는 순서도 중요합니다.
일반적인 상황에선 cardinality(구분명확도) 가 높은 컬럼을 보통 왼쪽으로 먼저 밀어넣습니다.
예를 들어 (이름, 주민번호) 이 컬럼이 있다면 주민번호 같이 중복이 없는 컬럼을 왼쪽부터 밀어넣어 (주민번호, 이름) ← 이런식으로 index를 만드는게 좋습니다.
참고하세용
SQL 쿼리로 index를 만들고 싶다면
CREATE INDEX 인덱스이름작명 ON 테이블명 (컬럼명);
참 쉽죠?
CREATE INDEX 인덱스이름작명 ON 테이블명 (컬럼명1, 컬럼명2);
다중컬럼 index 생성은 이런식입니다.
'DI(Digital Innovation) > DataBase & SQL 뽀개기' 카테고리의 다른 글
| 진짜 검색기록은 최종보스 Full Text Search (0) | 2024.04.02 |
|---|---|
| 솔로지옥 덱스말고 SQL index (0) | 2024.03.28 |
| procedure, function 안에서 쓸 수 있는 IF문법 (0) | 2024.03.28 |
| procedure 많이 만들기 싫다면? 파라미터로 해결하세요~ (0) | 2024.03.28 |
| procedure에서 많이 쓰는 변수 문법 (0) | 2024.03.28 |
저희가 지난 시간 까지 index를 만들어 놓으면 성능이 향상된다고 배웠습니다.
SELECT 가 얼마나 성능이 향상되었는지 확인해볼까요??
execution plan(실행 계획) 분석해보기
library.csv 파일을 가져와보겠습니다.
이 csv 파일은 6만건의 도서관 소장도서 정보가 저장되어있는 데이터셋입니다.
SELECT * FROM library WHERE 등록번호 = 'CEM97499'
근데 이게 생각보다 오래 걸리는 것 같습니다.
뭔가가 오래 걸리는 것 같으면 실행계획부터 분석하고 봐도 되는데요
원하는 SELECT 쿼리문에 커서 올리고 DBever 상단메뉴 SQL 편집기 → 실행계획보기를 누르면 실행계획이 출력됩니다.
이게 컴퓨터가 이 쿼리문을 어케 실행할지 계획을 보여주는건데요.
이걸보고 성능평가 같은것을 확인할 수 있습니다.
→ 이게 아니여도 SELECT 쿼리 왼쪽에 EXPLAIN 키워드 붙이고 실행해도 비슷합니다.
이런 것이 뜨는데용
cost 는 어림잡아 걸리는 시간이라고 생각하시면 됩니다. 낮으면 좋겠죠?
저희는 보통 몇천, 몇만 정도면 1초에 몇백건 실행해도 부담이 되진 않습니다. 근데 거의 10만 넘어가면서 부터는 많이 실행하면 컴퓨터의 부담을 주거나 병목현상이 일어날 수 있습니다.
그래서 이 경우엔 index를 통해 개선하는 것이 좋습니다.
access_type 혹은 type 은 ALL 만 피하시면 됩니다.
ALL이 무슨의미냐면 ALL이 기록되어 있으면 테이블 전체 행을 full scan한다는 소리여서 성능이 매우 낮아집니다.
ALL만 안나오면 됩니다.
보통 여기는 index, range, ref, const 이런것들이 들어가면 됩니다.
filtered 는 컴퓨터가 읽은 행을 출력결과에 넣는 비율인데
예를 들어 10개의 행을 읽었는데 1개의 행만 출력 결과에 나오게 하고싶으면 10%로 게산됩니다.
그래서 100%에 가까울수록 좋은데 수치가 정확한 건 아니라, 보조지표 정도로 보시면 될 것 같습니다.
나머지는 execution plan 읽는 법 참조해서 보십쇼
테이블에 index 생성하려면
그래서 만약 cost 가 너무 높아서 index를 만드려고 합니다.
이건 쉽습니다.
⬆️ 사실 DBeaver에서 indexes 메뉴를 지원해줍니다 ㅋ
거기서 우클릭 해 index 하나 씩 생성ㄱㄱ
⬆️ 그럼 창이 하나 뜨는데 원하는 컬럼하나 선택해서 확인누르고 저장 하면 끝입니다. 쉽쥬??
- 참고로 Btree(B+tree) 말고 다른 식으로 index 만들 수 있는데
Rtree는 2차원 좌표값을 저장한 컬럼일 때 사용가능합니다.(위도,경도)
Full text는 긴 문장에서 원하는 단어 빠르게 찾고 싶을때 씁니다.(글 검색 기능을 만들때 주로 사용) - UNIQUE 제약을 줘도 상관없는, 행마다 서로 다른 값을 가진 컬럼이라면 Unique를 체크해서 만들어두면 검색성능이 더빨라집니다. 이런걸 Unique index라고 합니다.
index 만든 후 성능을 다시 평가해보자구
SELECT * FROM library WHERE 등록번호 = 'CEM97499'
등록 번호 컬럼에 index 만들었으니 위 쿼리를 다시 실행 해보겠습니다.
그리고 커서 찍고 ‘실행계획보기’누르겠습니다.
[틀린그림찾기 - 키썸]
다들 하셨나요? 아까는 cost가 6천을 넘었는데 1로 감소했네요. access_type도 ALL에서 ref 로 변경되었네요..
그럼 이쯤에서 똑똑한 친구들은 질문이 있겠죠
??? : 전에 말한 것처럼 범위를 지정하면 더 빠르다면서 왜 WHERE 등록번호 < ‘CEM97499’ 같은 index 안쓰나요?
예리한 질문입니다.
현재 테이블의 전체 행은 거의 6만개입니다. 근데 이 쿼리를 출력하면 거의 3만개의 행이 출현합니다.
원래 범위 검색시 출력할 행들이 많아서 출력할 행이 전체 행의 20%를 넘게된다면 index를 굳이 안써도 된다고 DBMS 혼자 북치고 장구치고 판단하여 걍 index 안씁니다.
강제로 쓰라고 명령할수도 있는데요. 이건 알아서 판단하게 냅둡시다.
PRIMARY KEY인 경우
ALTER TABLE library ADD COLUMN id int PRIMARY KEY AUTO_INCREMENT;
libary 테이블에 id라는 pk를 만들어 봅시다.
그리고 id = 어쩌구 저쩌구 컬럼을 찾으라고 쿼리를 짜겠습니다.
이건 어케 나올까요?
직접 해보십쇼.
해보셨나요?
access_type이 const 이런식으로 나올텐데요
NOT NULL + PRIMARY KEY 역할을 하는 컬럼은 = 등호로 검색 시 const가 뜹니다. 빠르고 좋단 뜻
그래서 pk 컬럼은 기본적으로 검색이 매우 빠르기 때문에 index 신경쓸 필요 없습니다.
다중 컬럼 index
SELECT * FROM 아무개 WHERE name = 'park' AND age = 20
위 쿼리 처럼 에를 들어 컬럼 2개 이상에서 검색 작업을 수행할때는
그 컬럼들 각각 index를 만드는 것보다
필요한 컬럼들을 전부 묶어서 index를 만들어두면 성능이 더 향상됩니다.
index 만들 때 여러개의 컬럼도 선택 가능합니다.
⬆️ 별거 없습니다. 걍 여러개 체크하면 됨
체크한 순서대로 묶어서 index를 만듭니다.
이렇게 해두면 뭐가 좋냐?
예를 들어 님들이 a, b, c 컬럼이 있는데
이걸 (a, b, c) 이렇게 묶어서 index를 만들어뒀다면
a, b, c 컬럼 전부에 조건 걸어주는 쿼리를 짤때 컴퓨터가 알아서 사용한단 뜻입니다.
a, b, c 각각 index를 만드는 것보다 다중컬럼 index가 더빨라서 한꺼번에 씁시다.
예를들어 (name, age) 순으로 다중컬럼 index를 만들어 놓았더라면
WHERE name = ? AND age = ?
이런 쿼리를 작성할 때 그 (name, age) index를 사용해줍니다.
name, age를 각각 index 만드는 것보다 쿼리속도가 더 빠를 수 있음
WHERE name = ?
실은 이런 쿼리에도 그 (name, age) index를 사용해줍니다.
WHERE age = ??
근데 이건 (name, age) 이걸 사용할 수 없어요...
왜냐?
다중 컬럼 순서가 name 이 먼저기 때문에…
그래서 다중컬럼 index는 컬럼 넣는 순서도 중요합니다.
일반적인 상황에선 cardinality(구분명확도) 가 높은 컬럼을 보통 왼쪽으로 먼저 밀어넣습니다.
예를 들어 (이름, 주민번호) 이 컬럼이 있다면 주민번호 같이 중복이 없는 컬럼을 왼쪽부터 밀어넣어 (주민번호, 이름) ← 이런식으로 index를 만드는게 좋습니다.
참고하세용
SQL 쿼리로 index를 만들고 싶다면
CREATE INDEX 인덱스이름작명 ON 테이블명 (컬럼명);
참 쉽죠?
CREATE INDEX 인덱스이름작명 ON 테이블명 (컬럼명1, 컬럼명2);
다중컬럼 index 생성은 이런식입니다.
'DI(Digital Innovation) > DataBase & SQL 뽀개기' 카테고리의 다른 글
| 진짜 검색기록은 최종보스 Full Text Search (0) | 2024.04.02 |
|---|---|
| 솔로지옥 덱스말고 SQL index (0) | 2024.03.28 |
| procedure, function 안에서 쓸 수 있는 IF문법 (0) | 2024.03.28 |
| procedure 많이 만들기 싫다면? 파라미터로 해결하세요~ (0) | 2024.03.28 |
| procedure에서 많이 쓰는 변수 문법 (0) | 2024.03.28 |