
uipath에 뇌가 절여진 국나뇽…
오랜만에 파이썬으로 데이터 프레임 만지니까
너무 재밋고
데이터 만지는게 천직인가..?
방송사 시청률 받아오기 I
실습 설명
지난 시간에 DataFrame에서 원하는 부분을 선택하는 인덱싱을 배웠는데요. 이를 통해서 값을 찾는 연습을 해봅시다.
2016년도에 KBS방송국의 시청률을 찾아봅시다.
데이터를 한번 잘 살펴보고 어떻게 값을 찾아야 할지 고민해보세요!
주의 사항: 자동 채점 과제입니다. 정답 출력 코드는 print 없이 작성해 주세요. (예시: df)
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
# 여기에 코드를 작성하세요
df.loc[2016,'KBS']
df
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
df.loc[2016, 'KBS']
카드사 고객 분석
실습 설명
데이터의 중요성을 깨달은 “삼송카드”와 “현디카드”가 협업을 하기로 결정했습니다.
두 카드사는 사람들이 요일별로 지출하는 평균 금액을 “요일”, “식비", “교통비”, “문화생활비”, “기타” 카테고리로 정리해서 우리에게 공유해 주기로 했는데요. 각각 samsong.csv 파일과 hyundee.csv 파일을 보냈습니다.
두 회사의 데이터를 활용해서, 사람들의 요일별 문화생활비를 분석해보려 합니다. 아래와 같은 형태로 출력이 되도록 DataFrame을 만들어보세요.
실습 결과
day samsong hyundee
0 MON 4308 5339
1 TUE 7644 3524
2 WED 5674 5364
3 THU 8621 9942
4 FRI 23052 33511
5 SAT 15330 19397
6 SUN 19030 19925
import pandas as pd
samsong_df = pd.read_csv('data/samsong.csv')
hyundee_df = pd.read_csv('data/hyundee.csv')
# 여기에 코드를 작성하세요
new_df = pd.DataFrame({
'day' : samsong_df['요일'],
'samsong' : samsong_df['문화생활비'],
'hyundee' : hyundee_df['문화생활비']
})
new_df
import pandas as pd
samsong_df = pd.read_csv('data/samsong.csv')
hyundee_df = pd.read_csv('data/hyundee.csv')
combined_df = pd.DataFrame({
'day': samsong_df['요일'],
'samsong': samsong_df['문화생활비'],
'hyundee': hyundee_df['문화생활비']
})
combined_df
방송사 시청률 받아오기 II
실습 설명
이번에는 DataFrame에서 연속된 여러 줄을 찾는 연습을 해보겠습니다.
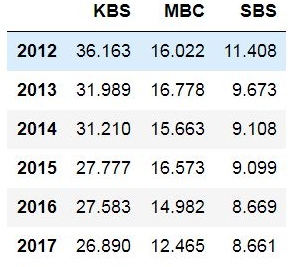
방송사는 'KBS'에서 'SBS'까지, 연도는 2012년부터 2017년까지의 시청률만 확인하려면 어떻게 하면 될까요?
실습 결과
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
# 여기에 코드를 작성하세요
df.loc[2012:2017,'KBS':'SBS']
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
df.loc[2012:2017, 'KBS':'SBS']
방송사 시청률 받아오기 III
실습 설명
이번에는 DataFrame에서 조건에 해당하는 데이터를 찾는 연습을 해보겠습니다.
'KBS'에서 시청률이 30이 넘은 데이터만 확인해보려면 어떻게 하면 될까요?
실습 결과
2011 35.951
2012 36.163
2013 31.989
2014 31.210
Name: KBS, dtype: float64
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
# 여기에 코드를 작성하세요
new_df = df.loc[df['KBS'] > 30,'KBS']
new_df
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
boolean_KBS = df['KBS'] > 30
df.loc[boolean_KBS, 'KBS']
방송사 시청률 받아오기 IV
실습 설명
이번에는 좀 더 DataFrame을 다방면으로 분석해봅시다.
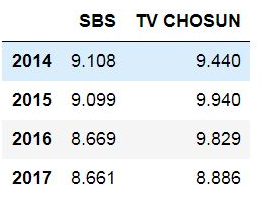
주어진 데이터에서 SBS가 TV CHOSUN보다 더 시청률이 낮았던 시기의 데이터를 확인해보려고 합니다.
어떻게 하면 될까요?
실습 결과
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
# 여기에 코드를 작성하세요
df[df['SBS'] < df['TV CHOSUN']][['SBS', 'TV CHOSUN']]
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
df.loc[df['SBS'] < df['TV CHOSUN'], ['SBS', 'TV CHOSUN']]
잘못된 DataFrame 고치기 I
실습 설명
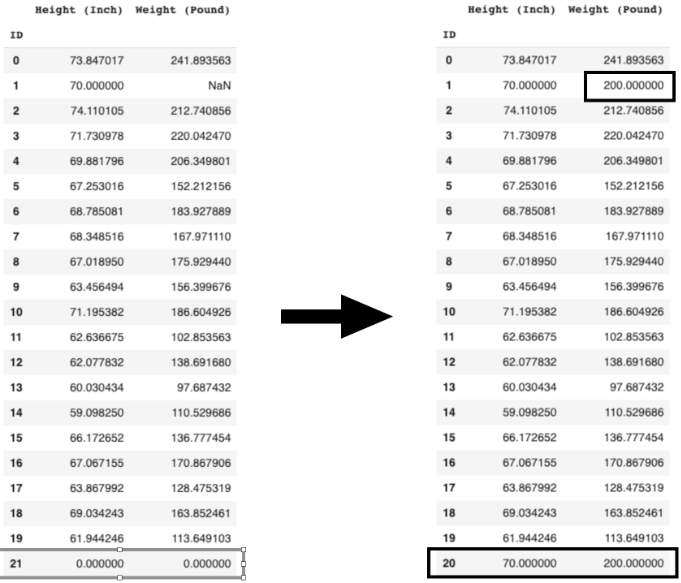
키와 몸무게가 담겨 있는 한 DataFrame이 있는데요. 몇 가지 잘못된 사항들이 있습니다. 이번 챕터에서 배운 기법들로 DataFrame을 바로잡아 봅시다.
해야 할 일이 세 가지 있습니다.
- ID 1의 무게를 200으로 변경하세요.
- ID 21의 row를 삭제하세요.
- ID 20의 row를 추가하세요. ID 20의 키는 70, 무게는 200입니다.
딱 3줄의 코드만 추가하시면 됩니다!
주의 사항: 자동 채점 과제입니다. 정답 출력 코드는 print 없이 작성해 주세요. (예시: df)
import pandas as pd
df = pd.read_csv('data/body_imperial1.csv', index_col=0)
# 여기에 코드를 작성하세요
df.iloc[1,1]=200
df.drop(21, axis='index', inplace=True)
df.loc[20] = [70,200]
# 테스트 코드
df
import pandas as pd
df = pd.read_csv('data/body_imperial1.csv', index_col=0)
# 데이터 고치기
df.loc[1,"Weight (Pound)"] = 200
df.drop(21, axis = "index", inplace = True)
df.loc[20] = [70,200]
# 테스트 코드
df
잘못된 DataFrame 고치기 II
실습 설명
키와 몸무게가 담겨 있는 한 DataFrame이 있는데요. 몇 가지 잘못된 사항들이 있습니다. 이번 챕터에서 배운 기법들로 DataFrame을 바로잡아 봅시다.
해야 할 일이 두 가지 있습니다.
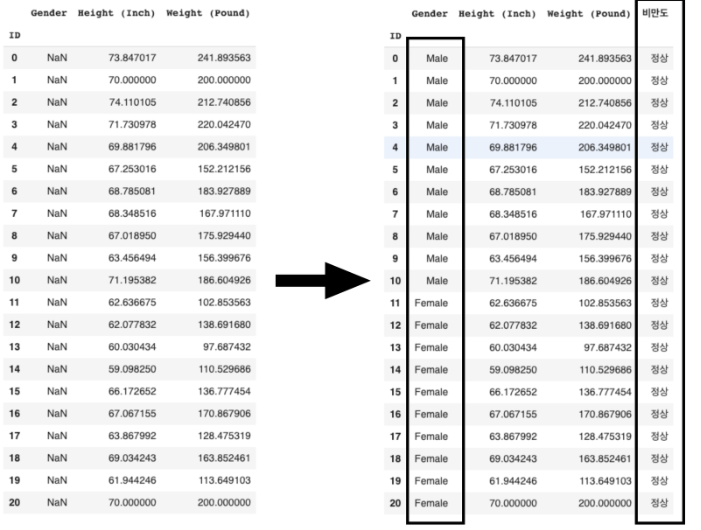
- '비만도' column을 추가하고, 모든 ID에 대해 '정상'으로 설정해주세요.
- 'Gender' column의 값을 ID 0~10까지는 'Male' 11~20까지는 'Female'로 변경하세요.
실습 결과
주의 사항: 자동 채점 과제입니다. 정답 출력 코드는 print 없이 작성해 주세요. (예시: df)
import pandas as pd
df = pd.read_csv('data/body_imperial2.csv', index_col=0)
# 여기에 코드를 작성하세요
df["비만도"] = "정상"
df.loc[:10,"Gender"] = "Male"
df.loc[11:,"Gender"] = "Female"
# 테스트 코드
df
# 데이터 읽기
import pandas as pd
df = pd.read_csv('data/body_imperial2.csv', index_col=0)
# 데이터 고치기
df["비만도"] = "정상"
df.loc[:10,"Gender"] = "Male"
df.loc[11:,"Gender"] = "Female"
# 정답 출력
df
서류전형 합격 여부
실습 설명
토익 시험은 LC(듣기) 파트와 RC(독해) 파트로 이루어져 있습니다. 각 파트가 495점 만점, 총 990점이 만점입니다.
“서울 항공”에 입사하기 위해서는 토익 점수를 제출해야 하는데요. 각 파트가 최소 250점, 총 점수가 최소 600점이 되어야 서류 전형을 합격할 수 있습니다.
기존 DataFrame에 “합격 여부”라는 column을 추가하고, 합격한 지원자는 불린 값 True, 불합격한 지원자는 불린 값 False를 넣어주면 됩니다.
실습 결과

주의 사항: 자동 채점 과제입니다. 정답 출력 코드는 print 없이 작성해 주세요. (예시: df)
import pandas as pd
df = pd.read_csv('data/toeic.csv')
# 여기에 코드를 작성하세요
df.loc[(df["LC"] + df['RC'] >= 600) and (df['LC'] >= 250) and (df['RC'] >= 250), "합격 여부"] = True
# 테스트 코드
df
import pandas as pd
df = pd.read_csv('data/toeic.csv')
pass_total = df['LC'] + df['RC'] >= 600
pass_both = (df['LC'] >= 250) & (df['RC'] >= 250)
df['합격 여부'] = pass_total & pass_both
# 테스트 코드
df
퍼즐을 풀어라!
실습 설명
데이터프레임이 있습니다.
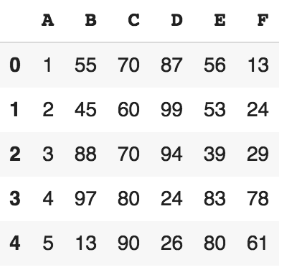
코드를 4줄만 써서, 아래 데이터프레임으로 바꿔보세요.
실습 결과
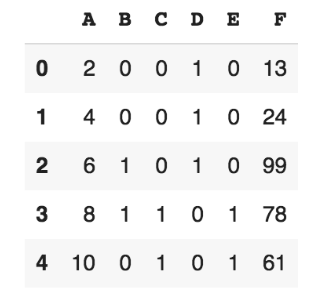
어느 부분이 바뀌었을까요?
주의 사항: 자동 채점 과제입니다. 정답 출력 코드는 print 없이 작성해 주세요. (예시: df)
규칙찾느라 애 좀 먹은 문제…
나는 아직도 리스트의 값 넣어서 리스트로 데이터프레임 컬럼을 채우는데 익숙해져이따…
확실히 공간, 시간 복잡도 면에서도 차이가 많이 날 것 같다.
loc 라이브러리 써서 하는 것도 연습 해봐야게따
import pandas as pd
df = pd.read_csv('data/Puzzle_before.csv')
# 여기에 코드를 작성하세요
df['A'] *= 2
b_list = []
c_list = []
d_list = []
e_list = []
for i in range(len(df)):
if df['B'][i] >= 80:
b_list.append(1)
else:
b_list.append(0)
for i in range(len(df)):
if df['C'][i] >= 80:
c_list.append(1)
else:
c_list.append(0)
for i in range(len(df)):
if df['D'][i] >= 80:
d_list.append(1)
else:
d_list.append(0)
for i in range(len(df)):
if df['E'][i] >= 80:
e_list.append(1)
else:
e_list.append(0)
df['B'] = b_list
df['C'] = c_list
df['D'] = d_list
df['E'] = e_list
df['F'][2] = 99
# 테스트 코드
df
import pandas as pd
df = pd.read_csv('data/Puzzle_before.csv')
df['A'] = df['A'] * 2
df[df.loc[:, 'B':'E'] < 80] = 0
df[df.loc[:, 'B':'E'] >= 80] = 1
df.loc[2, 'F'] = 99
# 테스트 코드
df
8주차 과정 실전 4주 압축과정으로 듣는 중
'DI(Digital Innovation) > HYUNDAI NGV in Data Analysis' 카테고리의 다른 글
| 주야경독(feat. HDAT 2) (2) | 2024.11.05 |
|---|---|
| 주경야독(feat. HDAT 1) (2) | 2024.11.05 |
| [NGV & KAP 데이터 분석 in 모빌리티] 4주차 (0) | 2024.08.07 |
| [NGV & KAP 데이터 분석 in 모빌리티] 2주차 (1) | 2024.08.01 |
| [NGV & KAP 데이터 분석 in 모빌리티] 1주차 (1) | 2024.07.22 |
uipath에 뇌가 절여진 국나뇽…
오랜만에 파이썬으로 데이터 프레임 만지니까
너무 재밋고
데이터 만지는게 천직인가..?
방송사 시청률 받아오기 I
실습 설명
지난 시간에 DataFrame에서 원하는 부분을 선택하는 인덱싱을 배웠는데요. 이를 통해서 값을 찾는 연습을 해봅시다.
2016년도에 KBS방송국의 시청률을 찾아봅시다.
데이터를 한번 잘 살펴보고 어떻게 값을 찾아야 할지 고민해보세요!
주의 사항: 자동 채점 과제입니다. 정답 출력 코드는 print 없이 작성해 주세요. (예시: df)
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
# 여기에 코드를 작성하세요
df.loc[2016,'KBS']
df
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
df.loc[2016, 'KBS']
카드사 고객 분석
실습 설명
데이터의 중요성을 깨달은 “삼송카드”와 “현디카드”가 협업을 하기로 결정했습니다.
두 카드사는 사람들이 요일별로 지출하는 평균 금액을 “요일”, “식비", “교통비”, “문화생활비”, “기타” 카테고리로 정리해서 우리에게 공유해 주기로 했는데요. 각각 samsong.csv 파일과 hyundee.csv 파일을 보냈습니다.
두 회사의 데이터를 활용해서, 사람들의 요일별 문화생활비를 분석해보려 합니다. 아래와 같은 형태로 출력이 되도록 DataFrame을 만들어보세요.
실습 결과
day samsong hyundee
0 MON 4308 5339
1 TUE 7644 3524
2 WED 5674 5364
3 THU 8621 9942
4 FRI 23052 33511
5 SAT 15330 19397
6 SUN 19030 19925
import pandas as pd
samsong_df = pd.read_csv('data/samsong.csv')
hyundee_df = pd.read_csv('data/hyundee.csv')
# 여기에 코드를 작성하세요
new_df = pd.DataFrame({
'day' : samsong_df['요일'],
'samsong' : samsong_df['문화생활비'],
'hyundee' : hyundee_df['문화생활비']
})
new_df
import pandas as pd
samsong_df = pd.read_csv('data/samsong.csv')
hyundee_df = pd.read_csv('data/hyundee.csv')
combined_df = pd.DataFrame({
'day': samsong_df['요일'],
'samsong': samsong_df['문화생활비'],
'hyundee': hyundee_df['문화생활비']
})
combined_df
방송사 시청률 받아오기 II
실습 설명
이번에는 DataFrame에서 연속된 여러 줄을 찾는 연습을 해보겠습니다.
방송사는 'KBS'에서 'SBS'까지, 연도는 2012년부터 2017년까지의 시청률만 확인하려면 어떻게 하면 될까요?
실습 결과
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
# 여기에 코드를 작성하세요
df.loc[2012:2017,'KBS':'SBS']
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
df.loc[2012:2017, 'KBS':'SBS']
방송사 시청률 받아오기 III
실습 설명
이번에는 DataFrame에서 조건에 해당하는 데이터를 찾는 연습을 해보겠습니다.
'KBS'에서 시청률이 30이 넘은 데이터만 확인해보려면 어떻게 하면 될까요?
실습 결과
2011 35.951
2012 36.163
2013 31.989
2014 31.210
Name: KBS, dtype: float64
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
# 여기에 코드를 작성하세요
new_df = df.loc[df['KBS'] > 30,'KBS']
new_df
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
boolean_KBS = df['KBS'] > 30
df.loc[boolean_KBS, 'KBS']
방송사 시청률 받아오기 IV
실습 설명
이번에는 좀 더 DataFrame을 다방면으로 분석해봅시다.
주어진 데이터에서 SBS가 TV CHOSUN보다 더 시청률이 낮았던 시기의 데이터를 확인해보려고 합니다.
어떻게 하면 될까요?
실습 결과
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
# 여기에 코드를 작성하세요
df[df['SBS'] < df['TV CHOSUN']][['SBS', 'TV CHOSUN']]
import pandas as pd
df = pd.read_csv('data/broadcast.csv', index_col=0)
df.loc[df['SBS'] < df['TV CHOSUN'], ['SBS', 'TV CHOSUN']]
잘못된 DataFrame 고치기 I
실습 설명
키와 몸무게가 담겨 있는 한 DataFrame이 있는데요. 몇 가지 잘못된 사항들이 있습니다. 이번 챕터에서 배운 기법들로 DataFrame을 바로잡아 봅시다.
해야 할 일이 세 가지 있습니다.
- ID 1의 무게를 200으로 변경하세요.
- ID 21의 row를 삭제하세요.
- ID 20의 row를 추가하세요. ID 20의 키는 70, 무게는 200입니다.
딱 3줄의 코드만 추가하시면 됩니다!
주의 사항: 자동 채점 과제입니다. 정답 출력 코드는 print 없이 작성해 주세요. (예시: df)
import pandas as pd
df = pd.read_csv('data/body_imperial1.csv', index_col=0)
# 여기에 코드를 작성하세요
df.iloc[1,1]=200
df.drop(21, axis='index', inplace=True)
df.loc[20] = [70,200]
# 테스트 코드
df
import pandas as pd
df = pd.read_csv('data/body_imperial1.csv', index_col=0)
# 데이터 고치기
df.loc[1,"Weight (Pound)"] = 200
df.drop(21, axis = "index", inplace = True)
df.loc[20] = [70,200]
# 테스트 코드
df
잘못된 DataFrame 고치기 II
실습 설명
키와 몸무게가 담겨 있는 한 DataFrame이 있는데요. 몇 가지 잘못된 사항들이 있습니다. 이번 챕터에서 배운 기법들로 DataFrame을 바로잡아 봅시다.
해야 할 일이 두 가지 있습니다.
- '비만도' column을 추가하고, 모든 ID에 대해 '정상'으로 설정해주세요.
- 'Gender' column의 값을 ID 0~10까지는 'Male' 11~20까지는 'Female'로 변경하세요.
실습 결과
주의 사항: 자동 채점 과제입니다. 정답 출력 코드는 print 없이 작성해 주세요. (예시: df)
import pandas as pd
df = pd.read_csv('data/body_imperial2.csv', index_col=0)
# 여기에 코드를 작성하세요
df["비만도"] = "정상"
df.loc[:10,"Gender"] = "Male"
df.loc[11:,"Gender"] = "Female"
# 테스트 코드
df
# 데이터 읽기
import pandas as pd
df = pd.read_csv('data/body_imperial2.csv', index_col=0)
# 데이터 고치기
df["비만도"] = "정상"
df.loc[:10,"Gender"] = "Male"
df.loc[11:,"Gender"] = "Female"
# 정답 출력
df
서류전형 합격 여부
실습 설명
토익 시험은 LC(듣기) 파트와 RC(독해) 파트로 이루어져 있습니다. 각 파트가 495점 만점, 총 990점이 만점입니다.
“서울 항공”에 입사하기 위해서는 토익 점수를 제출해야 하는데요. 각 파트가 최소 250점, 총 점수가 최소 600점이 되어야 서류 전형을 합격할 수 있습니다.
기존 DataFrame에 “합격 여부”라는 column을 추가하고, 합격한 지원자는 불린 값 True, 불합격한 지원자는 불린 값 False를 넣어주면 됩니다.
실습 결과
주의 사항: 자동 채점 과제입니다. 정답 출력 코드는 print 없이 작성해 주세요. (예시: df)
import pandas as pd
df = pd.read_csv('data/toeic.csv')
# 여기에 코드를 작성하세요
df.loc[(df["LC"] + df['RC'] >= 600) and (df['LC'] >= 250) and (df['RC'] >= 250), "합격 여부"] = True
# 테스트 코드
df
import pandas as pd
df = pd.read_csv('data/toeic.csv')
pass_total = df['LC'] + df['RC'] >= 600
pass_both = (df['LC'] >= 250) & (df['RC'] >= 250)
df['합격 여부'] = pass_total & pass_both
# 테스트 코드
df
퍼즐을 풀어라!
실습 설명
데이터프레임이 있습니다.
코드를 4줄만 써서, 아래 데이터프레임으로 바꿔보세요.
실습 결과
어느 부분이 바뀌었을까요?
주의 사항: 자동 채점 과제입니다. 정답 출력 코드는 print 없이 작성해 주세요. (예시: df)
규칙찾느라 애 좀 먹은 문제…
나는 아직도 리스트의 값 넣어서 리스트로 데이터프레임 컬럼을 채우는데 익숙해져이따…
확실히 공간, 시간 복잡도 면에서도 차이가 많이 날 것 같다.
loc 라이브러리 써서 하는 것도 연습 해봐야게따
import pandas as pd
df = pd.read_csv('data/Puzzle_before.csv')
# 여기에 코드를 작성하세요
df['A'] *= 2
b_list = []
c_list = []
d_list = []
e_list = []
for i in range(len(df)):
if df['B'][i] >= 80:
b_list.append(1)
else:
b_list.append(0)
for i in range(len(df)):
if df['C'][i] >= 80:
c_list.append(1)
else:
c_list.append(0)
for i in range(len(df)):
if df['D'][i] >= 80:
d_list.append(1)
else:
d_list.append(0)
for i in range(len(df)):
if df['E'][i] >= 80:
e_list.append(1)
else:
e_list.append(0)
df['B'] = b_list
df['C'] = c_list
df['D'] = d_list
df['E'] = e_list
df['F'][2] = 99
# 테스트 코드
df
import pandas as pd
df = pd.read_csv('data/Puzzle_before.csv')
df['A'] = df['A'] * 2
df[df.loc[:, 'B':'E'] < 80] = 0
df[df.loc[:, 'B':'E'] >= 80] = 1
df.loc[2, 'F'] = 99
# 테스트 코드
df
8주차 과정 실전 4주 압축과정으로 듣는 중
'DI(Digital Innovation) > HYUNDAI NGV in Data Analysis' 카테고리의 다른 글
| 주야경독(feat. HDAT 2) (2) | 2024.11.05 |
|---|---|
| 주경야독(feat. HDAT 1) (2) | 2024.11.05 |
| [NGV & KAP 데이터 분석 in 모빌리티] 4주차 (0) | 2024.08.07 |
| [NGV & KAP 데이터 분석 in 모빌리티] 2주차 (1) | 2024.08.01 |
| [NGV & KAP 데이터 분석 in 모빌리티] 1주차 (1) | 2024.07.22 |