
머신러닝.. 꽤나 맛있을지도..?
- Pandas(모듈)
- 새로운 자료구조 2개
- Series(1차원), DataFrame(2차원)
- 엑셀 데이터를 df로 만들기
- 컬럼 ⇒ 인덱스 ⇒ 데이터 값 순으로 가공
- 컬럼(사용할 컬럼 추리기, 컬렴명을 사용하기 좋게 바꾸기)
- 인덱스
- 데이터 값(결측 데이터 처리, 데이터 타입 체크)
- 시각화
- 데이터를 잘 이해하기 위해서, 살펴보기 위해서 ⇒ 현미경
- 카테고리 데이터(Countplot)
- 연속된 숫자 데이터(히스토그램)
- 관계 : 카테고리 + 숫자(boxplot)
- 숫자 + 숫자 (산포도)
- 머신러닝
- 사이킷런 ← 잘 만들어짐
- feature engineering
- 하이퍼 파라미터 세팅
- 모델 생성
- 모델 훈련(fit)
- 예측(predict), 검증(score)
- 머신러닝 데이터 나누기
- feature(2차원) // target(1차원)
- target이 있는 모델 ⇒ 지도 학습
- target ⇒ 카테고리 형 : 분류모델(classification)
- target ⇒ 연속된 수치형 : 회귀모델(regression)
- target이 없는 모델 ⇒ 비지도 학습
train_path = r'C:\\Users\\user\\Desktop\\데이터분석 in 모빌리티 산업\\실습 데이터\\캐글 타이타닉\\train.csv'
test_path = r'C:\\Users\\user\\Desktop\\데이터분석 in 모빌리티 산업\\실습 데이터\\캐글 타이타닉\\test.csv'
# 경로 앞에 r을 붙이는 이유 => 백슬래시(\\)를 이스케이프 문자 취급함
# 메타문자 : \\ + 정해진 알파벳 -> 문자열에 특수한 효과를 가져옴
# r을 쓰면 문자 그 자체로 인식해라는 뜻
df_train = pd.read_csv(train_path)
df_test = pd.read_csv(test_path)
# 결측데이터처리
# Name, Ticket, Cabin => 데이터로 추출
# 카테고리 데이터 => 수치형 데이터 변환 (인코딩)
# 숫자 데이터 => 스케일링
- Pandas(모듈)
- 새로운 자료구조 2개
- Series(1차원), DataFrame(2차원)
- 엑셀 데이터를 df로 만들기
- 컬럼 ⇒ 인덱스 ⇒ 데이터 값 순으로 가공
- 컬럼(사용할 컬럼 추리기, 컬렴명을 사용하기 좋게 바꾸기)
- 인덱스
- 데이터 값(결측 데이터 처리, 데이터 타입 체크)
- 시각화
- 데이터를 잘 이해하기 위해서, 살펴보기 위해서 ⇒ 현미경
- 카테고리 데이터(Countplot)
- 연속된 숫자 데이터(히스토그램)
- 관계 : 카테고리 + 숫자(boxplot)
- 숫자 + 숫자 (산포도)
- 머신러닝
- 사이킷런 ← 잘 만들어짐
- feature engineering
- 하이퍼 파라미터 세팅
- 모델 생성
- 모델 훈련(fit)
- 예측(predict), 검증(score)
- 머신러닝 데이터 나누기
- feature(2차원) // target(1차원)
- target이 있는 모델 ⇒ 지도 학습
- target ⇒ 카테고리 형 : 분류모델(classification)
- target ⇒ 연속된 수치형 : 회귀모델(regression)
- target이 없는 모델 ⇒ 비지도 학습
train_path = r'C:\\Users\\user\\Desktop\\데이터분석 in 모빌리티 산업\\실습 데이터\\캐글 타이타닉\\train.csv'
test_path = r'C:\\Users\\user\\Desktop\\데이터분석 in 모빌리티 산업\\실습 데이터\\캐글 타이타닉\\test.csv'
# 경로 앞에 r을 붙이는 이유 => 백슬래시(\\)를 이스케이프 문자 취급함
# 메타문자 : \\ + 정해진 알파벳 -> 문자열에 특수한 효과를 가져옴
# r을 쓰면 문자 그 자체로 인식해라는 뜻
df_train = pd.read_csv(train_path)
df_test = pd.read_csv(test_path)
# 결측데이터처리
# Name, Ticket, Cabin => 데이터로 추출
# 카테고리 데이터 => 수치형 데이터 변환 (인코딩)
# 숫자 데이터 => 스케일링
# 타이타닉 분석
# 1. 결측데이터 처리
df_train.isna().sum() # True -> 1 False -> 0
df_train.isna().sum() / len(df_train) * 100 # Canbin은 결측데이터가 많아서 채우는 의미가 없다
df_test.isna().sum() / len(df_test) * 100
# PassengerId 0.000000
# Pclass 0.000000
# Name 0.000000
# Sex 0.000000
# Age 20.574163
# SibSp 0.000000
# Parch 0.000000
# Ticket 0.000000
# Fare 0.239234
# Cabin 78.229665
# Embarked 0.000000
# 1.1 Embarked 결측 데이터 처리
df_train[df_train['Embarked'].isna()] # embarked 결측값 눈으로 확인하기
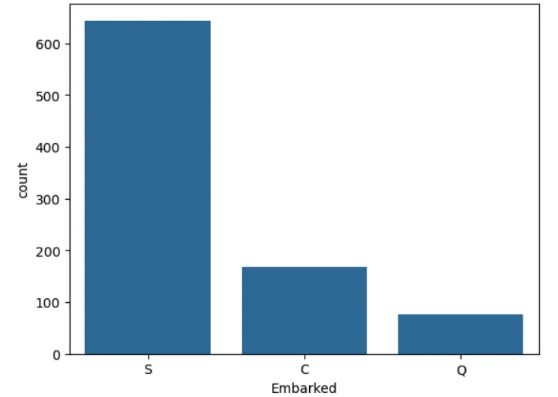
plt.figure()
sns.countplot(df_train, x='Embarked')
plt.show()
# 최빈도 값 => S -> C -> Q (카테고리형 데이터)
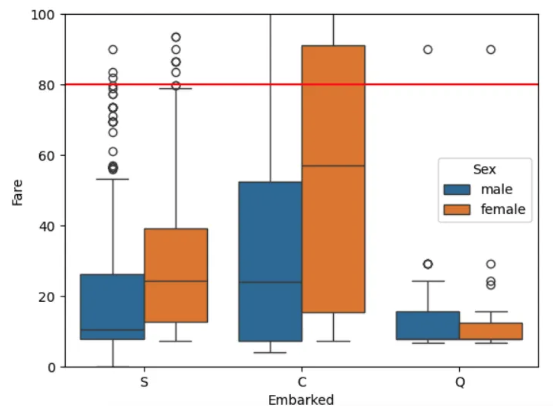
plt.figure()
sns.boxplot(df_train, x='Embarked', y='Fare', hue='Sex')
plt.ylim([0,100]) # y축 limit 설정
plt.axhline(80, color='red') # 80 값을 표시
plt.show()
# 아까 결측값들은 Fare가 80 이었음. S와 Q는 Fare==80이 outlier임
# 결측값들을 C로 하는 것이 좋을 것 같음
# 결측 데이터 덮어 씌우기
# 중간에 시리즈를 거치치 않고 데이터프레임에서 바로 바꿔줘야함! ex) df_train['Embarked'][61] X
# .loc 이용[조건, 컬럼] == .loc[인덱스, 컬럼]
df_train.loc[df_train['Embarked'].isna(),'Embarked'] = 'C'
# 1.2 Fare 결측값 처리
df_test[df_test['Fare'].isna()]
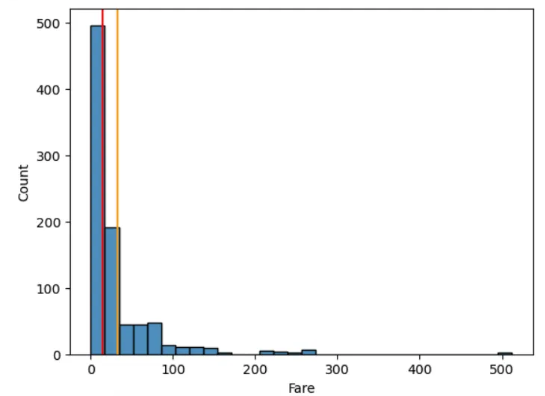
plt.figure()
sns.histplot(df_train, x='Fare', bins = 30)
plt.axvline(df_train['Fare'].mean(), color = 'orange')
plt.axvline(df_train['Fare'].median(), color = 'red')
plt.show()
# outlier가 평균을 오른쪽으로 이동시켜서 평균을 쓰면 안됨
# 이런 경우는 중앙값을 결측값으로 많이 채워넣음
plt.figure()
sns.boxplot(df_train, x='Pclass', y ='Fare', hue='Sex')
plt.show()
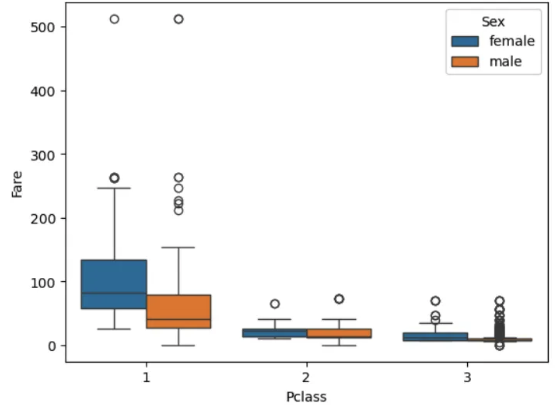
df_train.groupby(['Pclass', 'Sex'])['Fare'].median()
# Pclass Sex
# 1 female 82.66455
# male 41.26250
# 2 female 22.00000
# male 13.00000
# 3 female 12.47500
# male 7.92500
# Name: Fare, dtype: float64
df_test.loc[df_test['Fare'].isna(), 'Fare'] = 7.925
plt.figure()
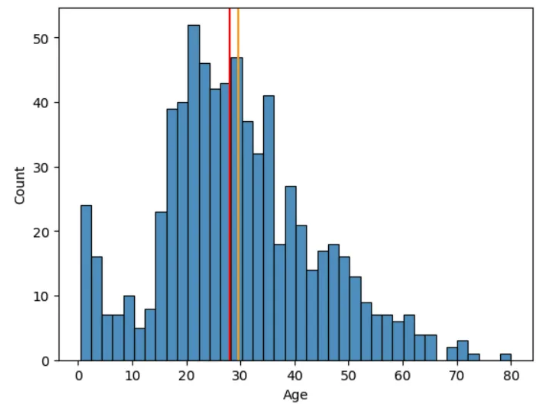
sns.histplot(df_train, x='Age', bins = 40)
plt.axvline(df_train['Age'].mean(), color = 'orange')
plt.axvline(df_train['Age'].median(), color = 'red')
plt.show()
# 아까 결측값들은 Fare가 80 이었음. S와 Q는 Fare==80이 outlier임
# 결측값들을 C로 하는 것이 좋을 것 같음
plt.figure()
sns.boxplot(df_train, x='Pclass', y ='Age', hue='Sex')
plt.show()
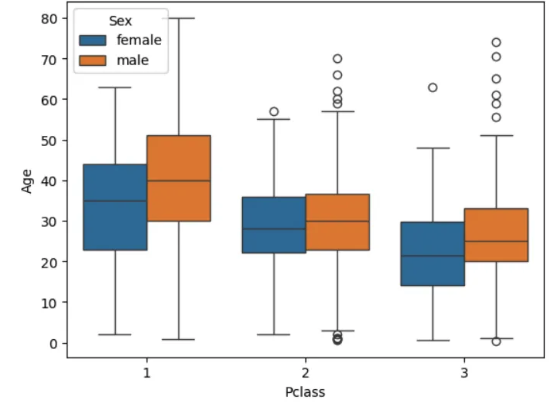
df_train.groupby(['Pclass', 'Sex'])['Age'].mean().round(1)
# Pclass Sex
# 1 female 34.6
# male 41.3
# 2 female 28.7
# male 30.7
# 3 female 21.8
# male 26.5
# Name: Age, dtype: float64
df_train.loc[(df_train['Age'].isna())&(df_train['Pclass'] == 1)&(df_train['Sex'] == 'female'), 'Age'] = 34.6
df_train.loc[(df_train['Age'].isna())&(df_train['Pclass'] == 1)&(df_train['Sex'] == 'male'), 'Age'] = 41.3
df_train.loc[(df_train['Age'].isna())&(df_train['Pclass'] == 2)&(df_train['Sex'] == 'female'), 'Age'] = 28.7
df_train.loc[(df_train['Age'].isna())&(df_train['Pclass'] == 2)&(df_train['Sex'] == 'male'), 'Age'] = 30.7
df_train.loc[(df_train['Age'].isna())&(df_train['Pclass'] == 3)&(df_train['Sex'] == 'female'), 'Age'] = 21.8
df_train.loc[(df_train['Age'].isna())&(df_train['Pclass'] == 3)&(df_train['Sex'] == 'male'), 'Age'] = 26.5
- Feature Engineering
- 숫자도 아니고 카테고리도 아닌 데이터들을 변형시켜줘서 둘 중 하나에 속하게 만들기
- 숫자 : 숫자들을 스탠다드 스케일링
- 카테고리 : 원핫 인코딩
- Feature들이 많으면 머신러닝 성능이 떨어짐 ⇒ 차원의 저주
2.1 Name
df_train['Name'] # 아직 데이터가 아님. 카테고리도 수치형 데이터도 아님
def get_name(x):
return x.split(', ',)[1].split('.')[0]
df_train['Name'].apply(get_name)
# 0 Mr
# 1 Mrs
# 2 Miss
# 3 Mrs
# 4 Mr
# ...
# 886 Rev
# 887 Miss
# 888 Miss
# 889 Mr
# 890 Mr
# Name: Name, Length: 891, dtype: object
df_train['Name2'] = df_train['Name'].apply(get_name)
plt.figure()
sns.countplot(df_train, x='Name2', hue='Survived')
plt.xticks(rotation=90)
plt.show()
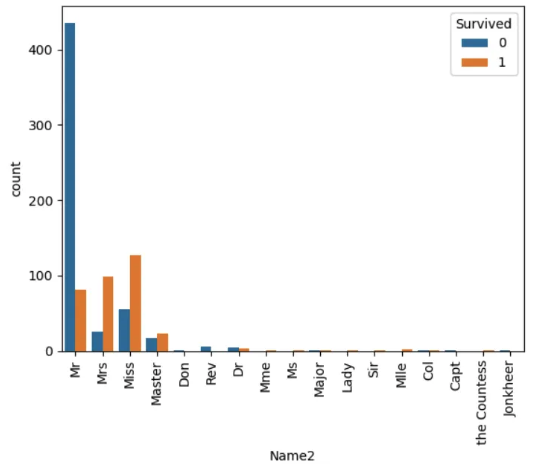
- 4가지 ⇒ 이거왜함? → feature 수 줄이기 위해서
- Mr
- Master
- Woman
- Etc
def to_categoryName(x):
if x == 'Mr':
return 'Mr'
elif x == 'Master':
return 'Master'
elif x in ['Mrs', 'Miss', 'Mme', 'Ms', 'Lady', 'Mlle']:
return 'Woman'
else:
return 'Etc'
df_train['Name_C'] = df_train['Name2'].apply(to_categoryName)
df_test['Name2'] = df_test['Name'].apply(get_name)
df_test['Name_C'] = df_test['Name2'].apply(to_categoryName)
df_test['Name_C'].unique()
2.2 Family
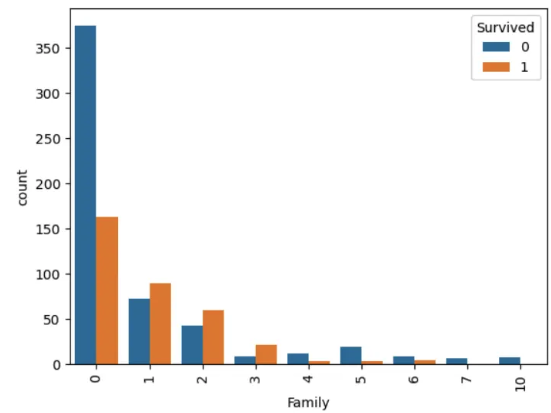
df_train['Family'] = df_train['SibSp'] + df_train['Parch']
plt.figure()
sns.countplot(df_train, x='Family', hue='Survived')
plt.xticks(rotation=90)
plt.show()
# 혼자탄사람 / 동반 숫자 적은사람 / 동반숫자 많은사람
def to_categoryFamily(x):
if x == 0:
return 'Alone'
elif x in [1,2,3]:
return 'Small_f'
else:
return 'Big_f'
df_train['Family_c'] = df_train['Family'].apply(to_categoryFamily)
df_train['Family_c'].unique()
# test 셋에도 똑같이 적용
df_test['Family'] = df_test['SibSp'] + df_test['Parch']
df_test['Family_c'] = df_test['Family'].apply(to_categoryFamily)
df_test['Family_c'].unique()
2.3 숫자데이터 스케일링 ⇒ Age, Fare → 스탠다드 스케일링
plt.figure(figsize=(5,3))
sns.histplot(df_train, x='Age', bins=35)
plt.show()
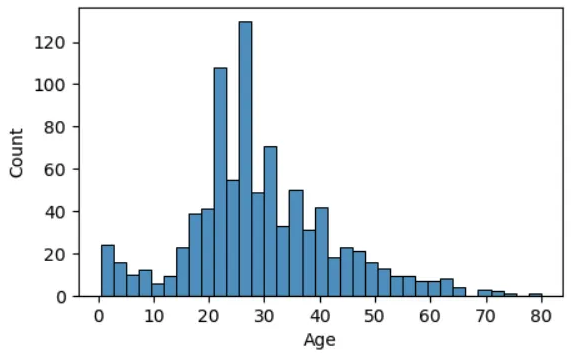
plt.figure(figsize=(5,3))
sns.histplot(df_train, x='Fare', bins=35)
plt.show()
# Outlier 때문에 망가져버림. 꼬리값을 누그려뜨려야함 => 로그변환을 하면 꼬리값의 값이 누그러뜨려짐(로그함수 참고 : 거리가 줄어듬)
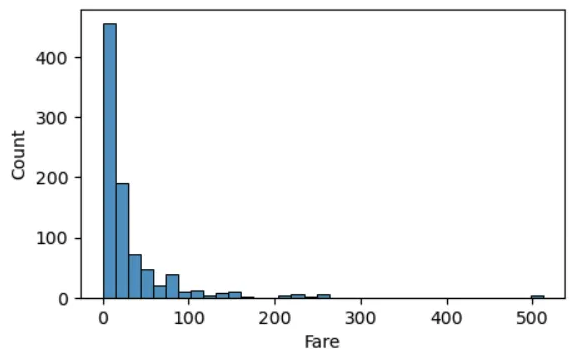
# Fare를 log 변환을 통해 꼬리값을 약화시키자
df_train['Fare_log'] = np.log(df_train['Fare']+1) # => numpy의 로그변환(0 이들어있으면 로그변환하면 무한대 값이 나와버림 그래서 x가 0인 경우를 대비해서 +1을하고 로그변환)
plt.figure(figsize=(5,3))
sns.histplot(df_train, x='Fare_log', bins=35)
plt.show()
# Outlier 때문에 망가져버림. 꼬리값을 누그려뜨려야함 => 로그변환을 하면 꼬리값의 값이 누그러뜨려짐(로그함수 참고 : 거리가 줄어듬)
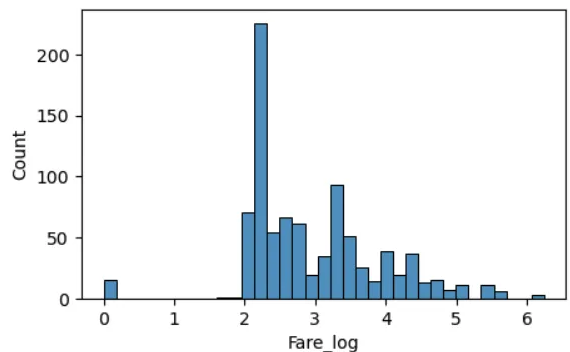
# Age와 Fare_log를 표준 스케일링 =
# 표준화 -> 평균으로 뺀다음에 표준편차로 나눠주기
age_mean = df_train['Age'].mean()
age_std = df_train['Age'].std()
# 이렇게 직접 계산하지 않음
# 직접 계산하지 않고 sklearn 이용
# 1. 스케일러 생성
# 2. 스케일러 훈련(train)
# 3. 실제 적용(train, test)
from sklearn.preprocessing import StandardScaler
# 1. 스케일러 생성
stndsclr = StandardScaler()
# 2. 스케일러를 훈련
stndsclr.fit(df_train[['Age', 'Fare_log']])
# 3. 실제 적용(train, test)
df_train[['Age_s', 'Fare_s']] = stndsclr.transform(df_train[['Age', 'Fare_log']])
# test 셋도 똑같이 해주기
df_test['Fare_log'] = np.log(df_test['Fare']+1)
df_test[['Age_s', 'Fare_s']] = stndsclr.transform(df_test[['Age', 'Fare_log']])
2.4 카테고리 데이터 인코딩
df_train.columns # 인코딩 해야하는 컬럼-> 'Pclass', 'Sex', 'Embarked', 'Name_C', 'Family_c'
cate_cols = ['Pclass', 'Sex', 'Embarked', 'Name_C', 'Family_c']
df_train_fin = pd.get_dummies(df_train, columns=cate_cols, dtype='int', drop_first=True) # 원핫인코딩
# 첫번째 feature를 100이 아니라 00으로 표현하도록(feature 수가 많아지면 안되니까) -> drop_first
df_test_fin = pd.get_dummies(df_test, columns=cate_cols, dtype='int', drop_first=True) # 원핫인코딩
# 첫번째 cols를 지워줌 -> drop_first
df_train_fin
2.5 데이터 정리
df_train_fin.columns
feature_names = ['Age_s', 'Fare_s',
'Pclass_2', 'Pclass_3', 'Sex_male', 'Embarked_Q', 'Embarked_S',
'Name_C_Master', 'Name_C_Mr', 'Name_C_Woman', 'Family_c_Big_f',
'Family_c_Small_f']
# 훈련할 feature와 target을 나눔
X = df_train_fin[feature_names] # 이제 우리가 머신러닝 돌리려는 컬럼만 남겨버림.
y = df_train_fin['Survived']
from sklearn.model_selection import train_test_split
train_x, valid_x, train_y, valid_y = train_test_split(X, y,
test_size=0.3,
random_state=1,
stratify=y)
- 머신러닝 모델 사용하여 예측
3.1 KNN
from sklearn.neighbors import KNeighborsClassifier # 타겟데이터 카테고리형 => classifier
from sklearn.model_selection import cross_val_score
# 하이퍼 파라미터 찾아보기
score_list = []
for k in range(1, 51):
knn = KNeighborsClassifier(n_neighbors=k)
score = cross_val_score(knn, train_x, train_y, cv=5).mean()
score_list.append(score)
plt.figure(figsize=(5,3))
plt.plot(range(1, 51), score_list, marker='o')
plt.show()
# 11이 best parmeter 같음.
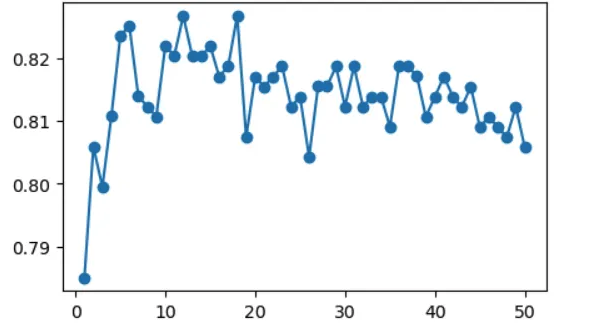
# k <= 11로 찾음!
# 1. 모델생성
knn_11 = KNeighborsClassifier(n_neighbors=11)
# 2. 훈련
knn_11.fit(train_x, train_y)
# 3. 검증
knn_11.score(valid_x, valid_y)
# 0.80579913487323
# 테스트 셋 예측
knn_11.predict(df_test_fin[feature_names])
# 테스트 셋 예측
knn_result = df_test_fin[['PassengerId']]
knn_result['Survived'] = knn_11.predict(df_test_fin[feature_names])
- SVM 써보기
- Cost ⇒ 경계선 근처에서 틀리는 것에 대한 비용
- 너무커지면 → 오버피팅
- 너무작으면 → 언더피팅
- 오버피팅과 적정피팅 사이에서 cost 찾기
- rdf → gamma(고차원에서 데이터의 형태를 얼마나 잘 피팅 시킬 것이냐)
- 너무 커지면 → 오버피팅
- 너무 작아지면 → 언더피팅
- poly → degree(몇 차 방정식 커널을 쓸거냐)
- 너무 커지면 → 오버피팅
- 너무 작아지면 → 언더피팅
- rdf → gamma(고차원에서 데이터의 형태를 얼마나 잘 피팅 시킬 것이냐)
- Cost ⇒ 경계선 근처에서 틀리는 것에 대한 비용
- 하이퍼 파라미터 찾아보기
- C, gamma
from sklearn.model_selection import GridSearchCV # 모든 경우의수를 자동으로 체크해주고 베스트를 찾아줌
from sklearn.svm import SVC
params = {'C':[0.01, 0.1, 1, 10], 'gamma':[0.01, 0.1, 1, 10]}
# 그리드 서치하는 모델이 생성
grid_svm = GridSearchCV(SVC(), params, cv=5)
# 모델에 데이터 넣고 피팅
grid_svm.fit(train_x, train_y)
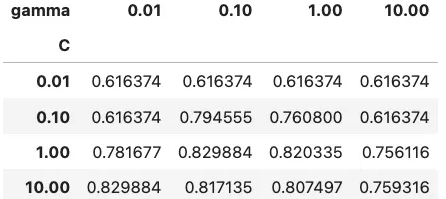
grid_svm.best_params_
# {'C': 1, 'gamma': 0.1}
svm_grid_result = pd.DataFrame(grid_svm.cv_results_['params'])
svm_grid_result['score'] = grid_svm.cv_results_['mean_test_score']
pd.pivot_table(svm_grid_result, index='C', columns='gamma', values='score', aggfunc = 'mean')
svm_result = df_test_fin[['PassengerId']]
svm_result['survived'] = grid_svm.predict(df_test_fin[feature_names])
3.3 tree
- 설명력! ⇒ gini 점수를 높은 질문을 하면서 순수한 데이터가 남을때까지 계속함(오버피팅 가능성이 많음 → 가지치기를 해서 줄여야함)
- 설명하긴 좋지만 오버피팅이 많이 됨 → 약한 트리 100개 만듬 → 랜덤 포레스트
from sklearn.tree import DecisionTreeClassifier, plot_tree
# DecisionTreeClassifier
# max_depth
# min_samples_leaf
params = {'max_depth':[3, 5, 10, 20], 'min_samples_leaf':[1, 10, 30]}
grid_tree = GridSearchCV(DecisionTreeClassifier(), params, cv=5)
grid_tree.fit(train_x, train_y)
grid_tree.best_params_
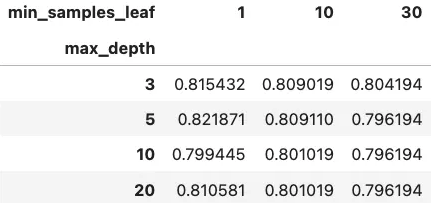
# {'max_depth': 5, 'min_samples_leaf': 1}
tree_grid_result = pd.DataFrame(grid_tree.cv_results_['params'])
tree_grid_result['score'] = grid_tree.cv_results_['mean_test_score']
pd.pivot_table(tree_grid_result, index='max_depth', columns='min_samples_leaf', values='score', aggfunc='mean')
tree = DecisionTreeClassifier(max_depth=5)
tree.fit(train_x, train_y)
tree.feature_importances_
# array([0.12665691, 0.07802374, 0.01475992, 0.07756979, 0.02860353,
# 0. , 0.00875188, 0. , 0.49796479, 0. ,
# 0.16434044, 0.00332901])
3.4 random forest
- 약한 나무 여러개를 심어서 예측력을 높이고 오버피팅 극복
- 다양성 2
- 사용할 feature들을 랜덤하게 선택
- 훈련하는 데이터를 bootstrap 이라는 샘플링 기법을 이용해서 나무마다 다르게 구성
from sklearn.ensemble import RandomForestClassifier
# max_depth
# min_samples_leaf
# RandomForestClassifier
params = {'max_depth':[3, 5, 10, 20], 'min_samples_leaf':[1, 10, 30]}
grid_randomforest = GridSearchCV(RandomForestClassifier(random_state=1), params, cv=5)
grid_randomforest.fit(train_x, train_y)
grid_randomforest.best_params_
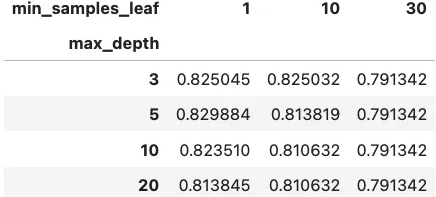
# {'max_depth': 5, 'min_samples_leaf': 1}
randomforest_grid_result = pd.DataFrame(grid_randomforest.cv_results_['params'])
randomforest_grid_result['score'] = grid_randomforest.cv_results_['mean_test_score']
pd.pivot_table(randomforest_grid_result, index='max_depth', columns='min_samples_leaf', values='score', aggfunc='mean')
grid_randomforest.score(valid_x, valid_y)
# 0.8283582089552238
rf_result = df_test_fin[['PassengerId']]
rf_result['Survived'] = grid_randomforest.predict(df_test_fin[feature_names])
- 타이타닉 ⇒ 숫자 데이터가 없음
- 공장데이터 ⇒ 숫자(결측데이터, 스케일링)
- EDA(탐색적 데이터 분석)
- 공식(카테고리, 연속된 숫자)
- 결측데이터
- 평균, 중앙값(수치형 데이터) / 최빈도 값(카테고리형 데이터)
- 다른 feature를 가지고 유추
- 머신러닝
- 특성가공
- 카테고리도 아니고, 숫자도 아닌 것들을 다 카테고리, 숫자로 바꾸기
- 스케일링
- 인코딩
'DI(Digital Innovation) > HYUNDAI NGV in Data Analysis' 카테고리의 다른 글
| 주경야독(feat. HDAT 1) (2) | 2024.11.05 |
|---|---|
| [NGV & KAP 데이터 분석 in 모빌리티] 4주차 (0) | 2024.08.07 |
| [NGV & KAP 데이터 분석 in 모빌리티] 3주차 (0) | 2024.08.07 |
| [NGV & KAP 데이터 분석 in 모빌리티] 2주차 (1) | 2024.08.01 |
| [NGV & KAP 데이터 분석 in 모빌리티] 1주차 (1) | 2024.07.22 |
머신러닝.. 꽤나 맛있을지도..?
- Pandas(모듈)
- 새로운 자료구조 2개
- Series(1차원), DataFrame(2차원)
- 엑셀 데이터를 df로 만들기
- 컬럼 ⇒ 인덱스 ⇒ 데이터 값 순으로 가공
- 컬럼(사용할 컬럼 추리기, 컬렴명을 사용하기 좋게 바꾸기)
- 인덱스
- 데이터 값(결측 데이터 처리, 데이터 타입 체크)
- 시각화
- 데이터를 잘 이해하기 위해서, 살펴보기 위해서 ⇒ 현미경
- 카테고리 데이터(Countplot)
- 연속된 숫자 데이터(히스토그램)
- 관계 : 카테고리 + 숫자(boxplot)
- 숫자 + 숫자 (산포도)
- 머신러닝
- 사이킷런 ← 잘 만들어짐
- feature engineering
- 하이퍼 파라미터 세팅
- 모델 생성
- 모델 훈련(fit)
- 예측(predict), 검증(score)
- 머신러닝 데이터 나누기
- feature(2차원) // target(1차원)
- target이 있는 모델 ⇒ 지도 학습
- target ⇒ 카테고리 형 : 분류모델(classification)
- target ⇒ 연속된 수치형 : 회귀모델(regression)
- target이 없는 모델 ⇒ 비지도 학습
train_path = r'C:\\Users\\user\\Desktop\\데이터분석 in 모빌리티 산업\\실습 데이터\\캐글 타이타닉\\train.csv'
test_path = r'C:\\Users\\user\\Desktop\\데이터분석 in 모빌리티 산업\\실습 데이터\\캐글 타이타닉\\test.csv'
# 경로 앞에 r을 붙이는 이유 => 백슬래시(\\)를 이스케이프 문자 취급함
# 메타문자 : \\ + 정해진 알파벳 -> 문자열에 특수한 효과를 가져옴
# r을 쓰면 문자 그 자체로 인식해라는 뜻
df_train = pd.read_csv(train_path)
df_test = pd.read_csv(test_path)
# 결측데이터처리
# Name, Ticket, Cabin => 데이터로 추출
# 카테고리 데이터 => 수치형 데이터 변환 (인코딩)
# 숫자 데이터 => 스케일링
- Pandas(모듈)
- 새로운 자료구조 2개
- Series(1차원), DataFrame(2차원)
- 엑셀 데이터를 df로 만들기
- 컬럼 ⇒ 인덱스 ⇒ 데이터 값 순으로 가공
- 컬럼(사용할 컬럼 추리기, 컬렴명을 사용하기 좋게 바꾸기)
- 인덱스
- 데이터 값(결측 데이터 처리, 데이터 타입 체크)
- 시각화
- 데이터를 잘 이해하기 위해서, 살펴보기 위해서 ⇒ 현미경
- 카테고리 데이터(Countplot)
- 연속된 숫자 데이터(히스토그램)
- 관계 : 카테고리 + 숫자(boxplot)
- 숫자 + 숫자 (산포도)
- 머신러닝
- 사이킷런 ← 잘 만들어짐
- feature engineering
- 하이퍼 파라미터 세팅
- 모델 생성
- 모델 훈련(fit)
- 예측(predict), 검증(score)
- 머신러닝 데이터 나누기
- feature(2차원) // target(1차원)
- target이 있는 모델 ⇒ 지도 학습
- target ⇒ 카테고리 형 : 분류모델(classification)
- target ⇒ 연속된 수치형 : 회귀모델(regression)
- target이 없는 모델 ⇒ 비지도 학습
train_path = r'C:\\Users\\user\\Desktop\\데이터분석 in 모빌리티 산업\\실습 데이터\\캐글 타이타닉\\train.csv'
test_path = r'C:\\Users\\user\\Desktop\\데이터분석 in 모빌리티 산업\\실습 데이터\\캐글 타이타닉\\test.csv'
# 경로 앞에 r을 붙이는 이유 => 백슬래시(\\)를 이스케이프 문자 취급함
# 메타문자 : \\ + 정해진 알파벳 -> 문자열에 특수한 효과를 가져옴
# r을 쓰면 문자 그 자체로 인식해라는 뜻
df_train = pd.read_csv(train_path)
df_test = pd.read_csv(test_path)
# 결측데이터처리
# Name, Ticket, Cabin => 데이터로 추출
# 카테고리 데이터 => 수치형 데이터 변환 (인코딩)
# 숫자 데이터 => 스케일링
# 타이타닉 분석
# 1. 결측데이터 처리
df_train.isna().sum() # True -> 1 False -> 0
df_train.isna().sum() / len(df_train) * 100 # Canbin은 결측데이터가 많아서 채우는 의미가 없다
df_test.isna().sum() / len(df_test) * 100
# PassengerId 0.000000
# Pclass 0.000000
# Name 0.000000
# Sex 0.000000
# Age 20.574163
# SibSp 0.000000
# Parch 0.000000
# Ticket 0.000000
# Fare 0.239234
# Cabin 78.229665
# Embarked 0.000000
# 1.1 Embarked 결측 데이터 처리
df_train[df_train['Embarked'].isna()] # embarked 결측값 눈으로 확인하기
plt.figure()
sns.countplot(df_train, x='Embarked')
plt.show()
# 최빈도 값 => S -> C -> Q (카테고리형 데이터)
plt.figure()
sns.boxplot(df_train, x='Embarked', y='Fare', hue='Sex')
plt.ylim([0,100]) # y축 limit 설정
plt.axhline(80, color='red') # 80 값을 표시
plt.show()
# 아까 결측값들은 Fare가 80 이었음. S와 Q는 Fare==80이 outlier임
# 결측값들을 C로 하는 것이 좋을 것 같음
# 결측 데이터 덮어 씌우기
# 중간에 시리즈를 거치치 않고 데이터프레임에서 바로 바꿔줘야함! ex) df_train['Embarked'][61] X
# .loc 이용[조건, 컬럼] == .loc[인덱스, 컬럼]
df_train.loc[df_train['Embarked'].isna(),'Embarked'] = 'C'
# 1.2 Fare 결측값 처리
df_test[df_test['Fare'].isna()]
plt.figure()
sns.histplot(df_train, x='Fare', bins = 30)
plt.axvline(df_train['Fare'].mean(), color = 'orange')
plt.axvline(df_train['Fare'].median(), color = 'red')
plt.show()
# outlier가 평균을 오른쪽으로 이동시켜서 평균을 쓰면 안됨
# 이런 경우는 중앙값을 결측값으로 많이 채워넣음
plt.figure()
sns.boxplot(df_train, x='Pclass', y ='Fare', hue='Sex')
plt.show()
df_train.groupby(['Pclass', 'Sex'])['Fare'].median()
# Pclass Sex
# 1 female 82.66455
# male 41.26250
# 2 female 22.00000
# male 13.00000
# 3 female 12.47500
# male 7.92500
# Name: Fare, dtype: float64
df_test.loc[df_test['Fare'].isna(), 'Fare'] = 7.925
plt.figure()
sns.histplot(df_train, x='Age', bins = 40)
plt.axvline(df_train['Age'].mean(), color = 'orange')
plt.axvline(df_train['Age'].median(), color = 'red')
plt.show()
# 아까 결측값들은 Fare가 80 이었음. S와 Q는 Fare==80이 outlier임
# 결측값들을 C로 하는 것이 좋을 것 같음
plt.figure()
sns.boxplot(df_train, x='Pclass', y ='Age', hue='Sex')
plt.show()
df_train.groupby(['Pclass', 'Sex'])['Age'].mean().round(1)
# Pclass Sex
# 1 female 34.6
# male 41.3
# 2 female 28.7
# male 30.7
# 3 female 21.8
# male 26.5
# Name: Age, dtype: float64
df_train.loc[(df_train['Age'].isna())&(df_train['Pclass'] == 1)&(df_train['Sex'] == 'female'), 'Age'] = 34.6
df_train.loc[(df_train['Age'].isna())&(df_train['Pclass'] == 1)&(df_train['Sex'] == 'male'), 'Age'] = 41.3
df_train.loc[(df_train['Age'].isna())&(df_train['Pclass'] == 2)&(df_train['Sex'] == 'female'), 'Age'] = 28.7
df_train.loc[(df_train['Age'].isna())&(df_train['Pclass'] == 2)&(df_train['Sex'] == 'male'), 'Age'] = 30.7
df_train.loc[(df_train['Age'].isna())&(df_train['Pclass'] == 3)&(df_train['Sex'] == 'female'), 'Age'] = 21.8
df_train.loc[(df_train['Age'].isna())&(df_train['Pclass'] == 3)&(df_train['Sex'] == 'male'), 'Age'] = 26.5
- Feature Engineering
- 숫자도 아니고 카테고리도 아닌 데이터들을 변형시켜줘서 둘 중 하나에 속하게 만들기
- 숫자 : 숫자들을 스탠다드 스케일링
- 카테고리 : 원핫 인코딩
- Feature들이 많으면 머신러닝 성능이 떨어짐 ⇒ 차원의 저주
2.1 Name
df_train['Name'] # 아직 데이터가 아님. 카테고리도 수치형 데이터도 아님
def get_name(x):
return x.split(', ',)[1].split('.')[0]
df_train['Name'].apply(get_name)
# 0 Mr
# 1 Mrs
# 2 Miss
# 3 Mrs
# 4 Mr
# ...
# 886 Rev
# 887 Miss
# 888 Miss
# 889 Mr
# 890 Mr
# Name: Name, Length: 891, dtype: object
df_train['Name2'] = df_train['Name'].apply(get_name)
plt.figure()
sns.countplot(df_train, x='Name2', hue='Survived')
plt.xticks(rotation=90)
plt.show()
- 4가지 ⇒ 이거왜함? → feature 수 줄이기 위해서
- Mr
- Master
- Woman
- Etc
def to_categoryName(x):
if x == 'Mr':
return 'Mr'
elif x == 'Master':
return 'Master'
elif x in ['Mrs', 'Miss', 'Mme', 'Ms', 'Lady', 'Mlle']:
return 'Woman'
else:
return 'Etc'
df_train['Name_C'] = df_train['Name2'].apply(to_categoryName)
df_test['Name2'] = df_test['Name'].apply(get_name)
df_test['Name_C'] = df_test['Name2'].apply(to_categoryName)
df_test['Name_C'].unique()
2.2 Family
df_train['Family'] = df_train['SibSp'] + df_train['Parch']
plt.figure()
sns.countplot(df_train, x='Family', hue='Survived')
plt.xticks(rotation=90)
plt.show()
# 혼자탄사람 / 동반 숫자 적은사람 / 동반숫자 많은사람
def to_categoryFamily(x):
if x == 0:
return 'Alone'
elif x in [1,2,3]:
return 'Small_f'
else:
return 'Big_f'
df_train['Family_c'] = df_train['Family'].apply(to_categoryFamily)
df_train['Family_c'].unique()
# test 셋에도 똑같이 적용
df_test['Family'] = df_test['SibSp'] + df_test['Parch']
df_test['Family_c'] = df_test['Family'].apply(to_categoryFamily)
df_test['Family_c'].unique()
2.3 숫자데이터 스케일링 ⇒ Age, Fare → 스탠다드 스케일링
plt.figure(figsize=(5,3))
sns.histplot(df_train, x='Age', bins=35)
plt.show()
plt.figure(figsize=(5,3))
sns.histplot(df_train, x='Fare', bins=35)
plt.show()
# Outlier 때문에 망가져버림. 꼬리값을 누그려뜨려야함 => 로그변환을 하면 꼬리값의 값이 누그러뜨려짐(로그함수 참고 : 거리가 줄어듬)
# Fare를 log 변환을 통해 꼬리값을 약화시키자
df_train['Fare_log'] = np.log(df_train['Fare']+1) # => numpy의 로그변환(0 이들어있으면 로그변환하면 무한대 값이 나와버림 그래서 x가 0인 경우를 대비해서 +1을하고 로그변환)
plt.figure(figsize=(5,3))
sns.histplot(df_train, x='Fare_log', bins=35)
plt.show()
# Outlier 때문에 망가져버림. 꼬리값을 누그려뜨려야함 => 로그변환을 하면 꼬리값의 값이 누그러뜨려짐(로그함수 참고 : 거리가 줄어듬)
# Age와 Fare_log를 표준 스케일링 =
# 표준화 -> 평균으로 뺀다음에 표준편차로 나눠주기
age_mean = df_train['Age'].mean()
age_std = df_train['Age'].std()
# 이렇게 직접 계산하지 않음
# 직접 계산하지 않고 sklearn 이용
# 1. 스케일러 생성
# 2. 스케일러 훈련(train)
# 3. 실제 적용(train, test)
from sklearn.preprocessing import StandardScaler
# 1. 스케일러 생성
stndsclr = StandardScaler()
# 2. 스케일러를 훈련
stndsclr.fit(df_train[['Age', 'Fare_log']])
# 3. 실제 적용(train, test)
df_train[['Age_s', 'Fare_s']] = stndsclr.transform(df_train[['Age', 'Fare_log']])
# test 셋도 똑같이 해주기
df_test['Fare_log'] = np.log(df_test['Fare']+1)
df_test[['Age_s', 'Fare_s']] = stndsclr.transform(df_test[['Age', 'Fare_log']])
2.4 카테고리 데이터 인코딩
df_train.columns # 인코딩 해야하는 컬럼-> 'Pclass', 'Sex', 'Embarked', 'Name_C', 'Family_c'
cate_cols = ['Pclass', 'Sex', 'Embarked', 'Name_C', 'Family_c']
df_train_fin = pd.get_dummies(df_train, columns=cate_cols, dtype='int', drop_first=True) # 원핫인코딩
# 첫번째 feature를 100이 아니라 00으로 표현하도록(feature 수가 많아지면 안되니까) -> drop_first
df_test_fin = pd.get_dummies(df_test, columns=cate_cols, dtype='int', drop_first=True) # 원핫인코딩
# 첫번째 cols를 지워줌 -> drop_first
df_train_fin
2.5 데이터 정리
df_train_fin.columns
feature_names = ['Age_s', 'Fare_s',
'Pclass_2', 'Pclass_3', 'Sex_male', 'Embarked_Q', 'Embarked_S',
'Name_C_Master', 'Name_C_Mr', 'Name_C_Woman', 'Family_c_Big_f',
'Family_c_Small_f']
# 훈련할 feature와 target을 나눔
X = df_train_fin[feature_names] # 이제 우리가 머신러닝 돌리려는 컬럼만 남겨버림.
y = df_train_fin['Survived']
from sklearn.model_selection import train_test_split
train_x, valid_x, train_y, valid_y = train_test_split(X, y,
test_size=0.3,
random_state=1,
stratify=y)
- 머신러닝 모델 사용하여 예측
3.1 KNN
from sklearn.neighbors import KNeighborsClassifier # 타겟데이터 카테고리형 => classifier
from sklearn.model_selection import cross_val_score
# 하이퍼 파라미터 찾아보기
score_list = []
for k in range(1, 51):
knn = KNeighborsClassifier(n_neighbors=k)
score = cross_val_score(knn, train_x, train_y, cv=5).mean()
score_list.append(score)
plt.figure(figsize=(5,3))
plt.plot(range(1, 51), score_list, marker='o')
plt.show()
# 11이 best parmeter 같음.
# k <= 11로 찾음!
# 1. 모델생성
knn_11 = KNeighborsClassifier(n_neighbors=11)
# 2. 훈련
knn_11.fit(train_x, train_y)
# 3. 검증
knn_11.score(valid_x, valid_y)
# 0.80579913487323
# 테스트 셋 예측
knn_11.predict(df_test_fin[feature_names])
# 테스트 셋 예측
knn_result = df_test_fin[['PassengerId']]
knn_result['Survived'] = knn_11.predict(df_test_fin[feature_names])
- SVM 써보기
- Cost ⇒ 경계선 근처에서 틀리는 것에 대한 비용
- 너무커지면 → 오버피팅
- 너무작으면 → 언더피팅
- 오버피팅과 적정피팅 사이에서 cost 찾기
- rdf → gamma(고차원에서 데이터의 형태를 얼마나 잘 피팅 시킬 것이냐)
- 너무 커지면 → 오버피팅
- 너무 작아지면 → 언더피팅
- poly → degree(몇 차 방정식 커널을 쓸거냐)
- 너무 커지면 → 오버피팅
- 너무 작아지면 → 언더피팅
- rdf → gamma(고차원에서 데이터의 형태를 얼마나 잘 피팅 시킬 것이냐)
- Cost ⇒ 경계선 근처에서 틀리는 것에 대한 비용
- 하이퍼 파라미터 찾아보기
- C, gamma
from sklearn.model_selection import GridSearchCV # 모든 경우의수를 자동으로 체크해주고 베스트를 찾아줌
from sklearn.svm import SVC
params = {'C':[0.01, 0.1, 1, 10], 'gamma':[0.01, 0.1, 1, 10]}
# 그리드 서치하는 모델이 생성
grid_svm = GridSearchCV(SVC(), params, cv=5)
# 모델에 데이터 넣고 피팅
grid_svm.fit(train_x, train_y)
grid_svm.best_params_
# {'C': 1, 'gamma': 0.1}
svm_grid_result = pd.DataFrame(grid_svm.cv_results_['params'])
svm_grid_result['score'] = grid_svm.cv_results_['mean_test_score']
pd.pivot_table(svm_grid_result, index='C', columns='gamma', values='score', aggfunc = 'mean')
svm_result = df_test_fin[['PassengerId']]
svm_result['survived'] = grid_svm.predict(df_test_fin[feature_names])
3.3 tree
- 설명력! ⇒ gini 점수를 높은 질문을 하면서 순수한 데이터가 남을때까지 계속함(오버피팅 가능성이 많음 → 가지치기를 해서 줄여야함)
- 설명하긴 좋지만 오버피팅이 많이 됨 → 약한 트리 100개 만듬 → 랜덤 포레스트
from sklearn.tree import DecisionTreeClassifier, plot_tree
# DecisionTreeClassifier
# max_depth
# min_samples_leaf
params = {'max_depth':[3, 5, 10, 20], 'min_samples_leaf':[1, 10, 30]}
grid_tree = GridSearchCV(DecisionTreeClassifier(), params, cv=5)
grid_tree.fit(train_x, train_y)
grid_tree.best_params_
# {'max_depth': 5, 'min_samples_leaf': 1}
tree_grid_result = pd.DataFrame(grid_tree.cv_results_['params'])
tree_grid_result['score'] = grid_tree.cv_results_['mean_test_score']
pd.pivot_table(tree_grid_result, index='max_depth', columns='min_samples_leaf', values='score', aggfunc='mean')
tree = DecisionTreeClassifier(max_depth=5)
tree.fit(train_x, train_y)
tree.feature_importances_
# array([0.12665691, 0.07802374, 0.01475992, 0.07756979, 0.02860353,
# 0. , 0.00875188, 0. , 0.49796479, 0. ,
# 0.16434044, 0.00332901])
3.4 random forest
- 약한 나무 여러개를 심어서 예측력을 높이고 오버피팅 극복
- 다양성 2
- 사용할 feature들을 랜덤하게 선택
- 훈련하는 데이터를 bootstrap 이라는 샘플링 기법을 이용해서 나무마다 다르게 구성
from sklearn.ensemble import RandomForestClassifier
# max_depth
# min_samples_leaf
# RandomForestClassifier
params = {'max_depth':[3, 5, 10, 20], 'min_samples_leaf':[1, 10, 30]}
grid_randomforest = GridSearchCV(RandomForestClassifier(random_state=1), params, cv=5)
grid_randomforest.fit(train_x, train_y)
grid_randomforest.best_params_
# {'max_depth': 5, 'min_samples_leaf': 1}
randomforest_grid_result = pd.DataFrame(grid_randomforest.cv_results_['params'])
randomforest_grid_result['score'] = grid_randomforest.cv_results_['mean_test_score']
pd.pivot_table(randomforest_grid_result, index='max_depth', columns='min_samples_leaf', values='score', aggfunc='mean')
grid_randomforest.score(valid_x, valid_y)
# 0.8283582089552238
rf_result = df_test_fin[['PassengerId']]
rf_result['Survived'] = grid_randomforest.predict(df_test_fin[feature_names])
- 타이타닉 ⇒ 숫자 데이터가 없음
- 공장데이터 ⇒ 숫자(결측데이터, 스케일링)
- EDA(탐색적 데이터 분석)
- 공식(카테고리, 연속된 숫자)
- 결측데이터
- 평균, 중앙값(수치형 데이터) / 최빈도 값(카테고리형 데이터)
- 다른 feature를 가지고 유추
- 머신러닝
- 특성가공
- 카테고리도 아니고, 숫자도 아닌 것들을 다 카테고리, 숫자로 바꾸기
- 스케일링
- 인코딩
'DI(Digital Innovation) > HYUNDAI NGV in Data Analysis' 카테고리의 다른 글
| 주경야독(feat. HDAT 1) (2) | 2024.11.05 |
|---|---|
| [NGV & KAP 데이터 분석 in 모빌리티] 4주차 (0) | 2024.08.07 |
| [NGV & KAP 데이터 분석 in 모빌리티] 3주차 (0) | 2024.08.07 |
| [NGV & KAP 데이터 분석 in 모빌리티] 2주차 (1) | 2024.08.01 |
| [NGV & KAP 데이터 분석 in 모빌리티] 1주차 (1) | 2024.07.22 |