
- Pandas
- 데이터 → 행과 열이 있는 2차원 데이터 테이블
- 테이블을 판다스로 직접 다룰 수 있음
- 2개의 새로운 자료구조를 제공 ⇒ Series, Dataframe
- Series
- 1차원 자료구조
- 구성요소 2개
- 순서가 있어서 슬라이싱과 for문 사용 가능
- Series의 기능들
- math_sr.sort_values(ascending=False) # D 100 # A 89 # C 48 # E 48 # B 39 # dtype: int64
- 필터링 → 조건을 이용해서 데이터를 가져오기
math_sr[math_sr < 50]
# B 39
# C 48
# E 48
# dtype: int64
eng = [89, 90, 91, 92, 100]
eng_sr = pd.Series(eng, index=['A', 'B', 'C', 'D', 'E'])
math_sr + eng_sr
# A 178
# B 129
# C 139
# D 192
# E 148
# dtype: int64
- DataFrame
- 2차원 자료구조
math = [89, 39, 48, 100, 48]
eng = [89, 90, 91, 92, 100]
kor = [50, 60, 70, 80, 90]
temp = {'math':math, 'eng':eng, 'kor':kor}
grade_df = pd.DataFrame(temp, index=['A', 'B', 'C', 'D', 'E'])
- 구성요소 3개 : Column, index, values
- 순서가 있음. 기본적으로 행
grade_df.loc['A']
# math 89
# eng 89
# kor 50
# Name: A, dtype: int64
# A학생의 수학점수
grade_dt.loc['A','math']
# 89
# df의 기능들
grade_df.sort_values(['kor','math'], ascending=False)
# 필터링
# 기준이되는 컬럼을 명확히 표시
grade_df[grade_df['math']>90]
# math eng kor
# D 100 92 80
# 조건이 여러개일때
# 연산 순서를 명확히 해줘야함
grade_df[(grade_df['math']>90) | (grade_df['eng']>90)]
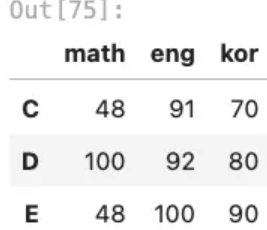
cond1 = grade_df['math']>90
cond2 = grade_df['eng']>90
cond3 = grade_df['kor']>90
grade_df[cond1 & cond2 & cond3]
- df 연습 → 타이타닉
import pandas as pd # 새로운 자료구조
import numpy as np # 행렬연산
import matplotlib.pyplot as plt # 시각화
import seaborn as sns # 시각화 도우미
titanic_df = sns.load_dataset('titanic')
titanic_df['survived']
sur_count = 0
dead_count = 0
for val in titanic_df['survived']:
if val == 1:
sur_count += 1
else:
dead_count += 1
print(sur_count)
print(dead_count)
# 342
# 549
titanic_df['survived'].value_counts()
# survived
# 0 549
# 1 342
# 성별에 따른 생존률
titanic_df['sex'].unique()
titanic_df['sex'] == 'male'
male = titanic_df[titanic_df['sex'] == 'male']
male['survived'].value_counts(normalize = True)
# survived
# 0 0.811092
# 1 0.188908
# Name: proportion, dtype: float64
# 타이타닉 주인공 찾기
# 남자
# 죽었음
# 3등석
# 20이상 25미만
cond1 = titanic_df['sex'] == 'male'
cond2 = titanic_df['survived'] == 0
cond3 = titanic_df['pclass'] == 3
cond4 = (titanic_df['age'] >= 20) & (titanic_df['age'] < 25)
main_titanic = titanic_df[cond1 & cond2 & cond3 & cond4]
- df 연습 → 졸업생 진로 현황 데이터
# 엑셀 데이터 데이터프레임으로 불러오기
# header, indx_col, usecols, skiprows, na_values
# 첫번째 행부터 읽어옴 => 첫번째 행을 컬럼으로 셋팅
# column => index => values 순으로 정리
path = r'C:\\Users\\user\\Desktop\\데이터분석 in 모빌리티 산업\\실습 데이터\\졸업생 진로 현황 데이터\\졸업생의 진로 현황(전체).xlsx'
df = pd.read_excel(path, sheet_name=0)
# 컬럼 정리
# 1. 사용할 컬럼 추리기
# 2. 컬럼명을 사용하기 좋게 바꾸기
df.columns
sel_col = ['지역', '정보공시 \\n 학교코드', '학교명', '졸업자.2', '(특수목적고)과학고 진학자.2', '(특수목적고)외고ㆍ국제고 진학자.2']
df_1 = df[sel_col]
df_1.columns = ['reg', 'code', 'name', 'grads', 'sci', 'intl']
# 컬럼의 찌꺼지 삭제하기
df_1=df_1.drop(0)
# index
# 보통의 경유 번호로 많이 함
# 시계열 데이터인 경우 인덱스 시간 형식으로 세팅
# values
# 1. 결측 데이터(NaN) 처리
# 2. 데이터 타입 체크
# 결측데이터 집계
df_1.isna().sum()
# reg 2
# code 0
# name 0
# grads 34
# sci 34
# intl 34
# dtype: int64
# 필터링
df_1[df_1['reg'].isna()]
df_2=df_1.dropna()
# 데이터 타입체크 (dtype)
# int => int32, int64
# float => float32, float64
# => datetime
# object(나머지)
df_2['grads'] = pd.to_numeric(df_2['grads'])
df_2['sci'] = pd.to_numeric(df_2['sci'])
df_2['intl'] = pd.to_numeric(df_2['intl'])
df_2.dtypes
# reg object
# code object
# name object
# grads int64
# sci int64
# intl int64
# dtype: object
df_5 = df_2.reset_index(drop=True)
# df의 주요기능들
# 시리즈의 연산, 필터링, apply, groupby, pivot
# 시리즈의 연산
df_5['spc'] = df_5['sci'] + df_5['intl']
df_5['spc_ratio'] = (df_5['spc'] / df_5['grads'] *100).round(2)
# 특목고 진학율 높은 top 50
df_5.sort_values('spc_ratio', ascending=False)[:20]
# 졸업생 100명 이상인 학교 중 특목고 진학율 top 20
df_6 = df_5[df_5['grads']>=100]
df_6.sort_values('spc_ratio', ascending=False).head(20)
# 과고 외고 진학자가 최소 1명 이상인 학교중 특목고 진학율 top20
cond1 = df_5['sci']>=1
cond2 = df_5['intl']>=1
temp = df_5[cond1 & cond2]
temp.sort_values('spc_ratio', ascending=False).head(20)
test = '서울특별시 노원구'
test.split(' ')
# ['서울특별시', '노원구']
def get_sido(x):
return x.split(' ')[0]
# apply
# 한열에 모든 데이터에게 똑같은 코드를 적용
df_5['sido'] = df_5['reg'].apply(get_sido)
df_5[df_5['sido'] == '서울특별시'].sort_values('spc_ratio', ascending=False).head(20)
# 집계 - 여러개의 데이터를 하나의 숫자나 문자로 축약해서 봄
# mean, sum, max, min
df_5.mean(numeric_only = True)
titanic_df.groupby(['sex', 'pclass', 'embarked'])['survived'].mean()
# alone
# False 0.505650
# True 0.303538
# Name: survived, dtype: float64
# pivot
# 카테고리별로 2차원으로 묶어서 집계
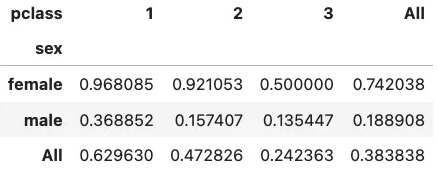
pd.pivot_table(titanic_df,
columns='pclass',
index='sex',
values='survived',
aggfunc='mean', margins=True)
import matplotlib.pyplot as plt
# 그래프 크기 설정
plt.figure(figsize=(8, 5))
# 첫 번째 데이터 시리즈
plt.plot([2, 1, 4, 2, 5, 1], marker='o', color='skyblue', label='Series 1', linewidth=2)
# 두 번째 데이터 시리즈
plt.plot([2, 5, 7, 2, 4, 1], marker='s', color='salmon', label='Series 2', linewidth=2)
# 그래프 제목 및 축 레이블 설정
plt.title('Stylized Line Plot', fontsize=16)
plt.xlabel('X-axis', fontsize=12)
plt.ylabel('Y-axis', fontsize=12)
# 그리드 추가
plt.grid(True, linestyle='--', alpha=0.7)
# 범례 추가
plt.legend(title='Data Series', fontsize=10)
# 그래프 여백 조정
plt.tight_layout()
# 그래프 보여주기
plt.show()
## 시각화의 목적
# 남들에게 분석결과 공유
# 스스로 데이터를 이해하기 위해서 (데이터를 보기위한 현미경)
# 데이터 타입에 따라 적절한 시각화 정리
# 데이터 타입 => 카테고리 데이터, 연속된 숫자 데이터
## 1. 연속된 숫자 데이터
# 분포 -> 데이터가 어디에 몰려있고, 어디에 퍼져있는지 살펴보기
# 히스토그램
# plt.hist, sns.histplot
df_5['sido'].unique()
big_city = ['서울특별시', '부산광역시', '대구광역시', '인천광역시', '광주광역시', '대전광역시', '울산광역시', '경기도']
def is_bigcidty(x):
if x in big_city:
return 'bigcity'
else:
return 'smallcity'
df_5['is_bigcity'] = df_5['sido'].apply(is_bigcidty)
### 카테고리 데이터
# 카테고리 별 데이터의 갯수
plt.figure(figsize=(12,3))
sns.countplot(df_5, x='sido')
plt.xticks(rotation=90)
plt.show()
##3. 카테고리 데이터와 숫자 데이터간의 비교
# 카테고리 별 숫자 데이터의 분포
# sns의 boxplot, violinplot
plt.figure()
sns.violinplot(titanic_df, x='pclass', y='fare', hue = 'sex')
plt.show()
# 머신러닝
# 사이킷런 : 머신러닝 모듈
iris_df = sns.load_dataset('iris')
plt.figure()
sns.pairplot(iris_df, hue='species')
plt.show()

- KNN(K Nearest Neighbors)
- neighbors ⇒ 거리
- 새로운 데이터 / 기존 데이터와 거리를 계산
- 거리가 짧은 n개를 살펴봄
- 이 데이터들의 target을 살펴보고 다수결
- Scikit learn 사용법
- 모델을 생성
- 모델을 훈련
- 예측, 검정
from sklearn.neighbors import KNeighborsClassifier
# 1. 모델을 생성
knn = KNeighborsClassifier()
# 2. 모델을 훈련
# feature와 target을 분리
# target은 무조건 1차원
# feature는 무조건 2차원
y = iris_df['species']
X = iris_df.iloc[ : , : -1 ]
knn.fit(X, y)
# 3. 예측, 검정
knn.predict([[5.0, 3.3, 1.45, 0.15]])
# 훈련용 데이터와 검증용 데이터로 나누기
# 8대 2로 나누기
# 섞어서 나눠야 함.(그럴줄알고 사이킷 런은 다 준비해놨어)
from sklearn.model_selection import train_test_split
train_x, valid_x, train_y, valid_y = train_test_split(X, y,
test_size=0.2,
random_state=77,
stratify=y) # random_state : 재현성(맞춰주기)
# 1. 모델을 생성
knn = KNeighborsClassifier()
# 2. 모델을 훈련(fit)
knn.fit(train_x, train_y)
# 3. 예측, 검증(socre)
knn.predict(valid_x) == valid_y # 1
knn.score(valid_x, valid_y) # 2
# 1. 하이퍼 파라미터 세팅
# 2. 모델을 생성
# 3. 모델을 훈련
# 4. 예측, 검증
# 교차 검증 => 적은 데이터를 n등분을 해서 그 중 에서 훈련 검증을 교차로 하는 것
# 마지막으로 평균내고 합친 것 모든데이터 훈련 / 모든 데이터 검증
from sklearn.model_selection import cross_val_score
knn_1 = KNeighborsClassifier(n_neighbors=1)
cross_val_score(knn_1, train_x, train_y, cv=4).mean()
knn_5 = KNeighborsClassifier(n_neighbors=5)
cross_val_score(knn_5, train_x, train_y, cv=4).mean()
# 0.94166666666666666667
- 요령이 있음. 어렴풋이 골라야함. 정확히 딱 정해지지가 않음
- k가 1일때, 주변에 1개 데이터만 보는 것 ⇒ 새로운 예측값이 위치가 살짝만 바뀌어도 불안정함(오버피팅)
- 반대로 k를 무한대로 설정한다면 ⇒ 그냥 제일 많은 빈도의 데이터를 예측값으로 줌(⇒ 평균값으로 예측하는 것 뿐임)
- 하이퍼 파라미터는 오버와 언더피팅 그사이에 적절한 선을 찾는 것
- 어떻게 찾을 것이냐?
- 변곡점 찾기, 이 값을 정확히 찾는 것은 불가능함
- 여러가지 데이터를 넣어서 올라가다 떨어지는 부분을 찾는거임
# 1~30까지 바꿔가며 교차검증을 해보자
score_list = []
for k in range(1, 31):
knn = KNeighborsClassifier(n_neighbors = k)
score = cross_val_score(knn, train_x, train_y, cv=4).mean()
score_list.append(score)
plt.figure()
plt.plot(range(1, 31), score_list)
plt.show()

# iris_df 데이터가 좋은이유? 거리로 계산할라면 => 거리여야함
# 이거는 이미 다 스케일링도 되어있고, 숫자로 되어있음. bias가 일어날 수가 없다.
iris_df['sepal_length'] = iris_df['sepal_length'] * 1000
- 카테고리 형 데이터 → 수치형 데이터 → 스케일링
- feature engineering(가장 중요)
- 하이퍼 파라미터 세팅
- 모델을 생성
- 모델을 훈련
- 예측, 검증
'DI(Digital Innovation) > HYUNDAI NGV in Data Analysis' 카테고리의 다른 글
| 주야경독(feat. HDAT 2) (2) | 2024.11.05 |
|---|---|
| [NGV & KAP 데이터 분석 in 모빌리티] 4주차 (0) | 2024.08.07 |
| [NGV & KAP 데이터 분석 in 모빌리티] 3주차 (0) | 2024.08.07 |
| [NGV & KAP 데이터 분석 in 모빌리티] 2주차 (1) | 2024.08.01 |
| [NGV & KAP 데이터 분석 in 모빌리티] 1주차 (1) | 2024.07.22 |
- Pandas
- 데이터 → 행과 열이 있는 2차원 데이터 테이블
- 테이블을 판다스로 직접 다룰 수 있음
- 2개의 새로운 자료구조를 제공 ⇒ Series, Dataframe
- Series
- 1차원 자료구조
- 구성요소 2개
- 순서가 있어서 슬라이싱과 for문 사용 가능
- Series의 기능들
- math_sr.sort_values(ascending=False) # D 100 # A 89 # C 48 # E 48 # B 39 # dtype: int64
- 필터링 → 조건을 이용해서 데이터를 가져오기
math_sr[math_sr < 50]
# B 39
# C 48
# E 48
# dtype: int64
eng = [89, 90, 91, 92, 100]
eng_sr = pd.Series(eng, index=['A', 'B', 'C', 'D', 'E'])
math_sr + eng_sr
# A 178
# B 129
# C 139
# D 192
# E 148
# dtype: int64
- DataFrame
- 2차원 자료구조
math = [89, 39, 48, 100, 48]
eng = [89, 90, 91, 92, 100]
kor = [50, 60, 70, 80, 90]
temp = {'math':math, 'eng':eng, 'kor':kor}
grade_df = pd.DataFrame(temp, index=['A', 'B', 'C', 'D', 'E'])
- 구성요소 3개 : Column, index, values
- 순서가 있음. 기본적으로 행
grade_df.loc['A']
# math 89
# eng 89
# kor 50
# Name: A, dtype: int64
# A학생의 수학점수
grade_dt.loc['A','math']
# 89
# df의 기능들
grade_df.sort_values(['kor','math'], ascending=False)
# 필터링
# 기준이되는 컬럼을 명확히 표시
grade_df[grade_df['math']>90]
# math eng kor
# D 100 92 80
# 조건이 여러개일때
# 연산 순서를 명확히 해줘야함
grade_df[(grade_df['math']>90) | (grade_df['eng']>90)]
cond1 = grade_df['math']>90
cond2 = grade_df['eng']>90
cond3 = grade_df['kor']>90
grade_df[cond1 & cond2 & cond3]
- df 연습 → 타이타닉
import pandas as pd # 새로운 자료구조
import numpy as np # 행렬연산
import matplotlib.pyplot as plt # 시각화
import seaborn as sns # 시각화 도우미
titanic_df = sns.load_dataset('titanic')
titanic_df['survived']
sur_count = 0
dead_count = 0
for val in titanic_df['survived']:
if val == 1:
sur_count += 1
else:
dead_count += 1
print(sur_count)
print(dead_count)
# 342
# 549
titanic_df['survived'].value_counts()
# survived
# 0 549
# 1 342
# 성별에 따른 생존률
titanic_df['sex'].unique()
titanic_df['sex'] == 'male'
male = titanic_df[titanic_df['sex'] == 'male']
male['survived'].value_counts(normalize = True)
# survived
# 0 0.811092
# 1 0.188908
# Name: proportion, dtype: float64
# 타이타닉 주인공 찾기
# 남자
# 죽었음
# 3등석
# 20이상 25미만
cond1 = titanic_df['sex'] == 'male'
cond2 = titanic_df['survived'] == 0
cond3 = titanic_df['pclass'] == 3
cond4 = (titanic_df['age'] >= 20) & (titanic_df['age'] < 25)
main_titanic = titanic_df[cond1 & cond2 & cond3 & cond4]
- df 연습 → 졸업생 진로 현황 데이터
# 엑셀 데이터 데이터프레임으로 불러오기
# header, indx_col, usecols, skiprows, na_values
# 첫번째 행부터 읽어옴 => 첫번째 행을 컬럼으로 셋팅
# column => index => values 순으로 정리
path = r'C:\\Users\\user\\Desktop\\데이터분석 in 모빌리티 산업\\실습 데이터\\졸업생 진로 현황 데이터\\졸업생의 진로 현황(전체).xlsx'
df = pd.read_excel(path, sheet_name=0)
# 컬럼 정리
# 1. 사용할 컬럼 추리기
# 2. 컬럼명을 사용하기 좋게 바꾸기
df.columns
sel_col = ['지역', '정보공시 \\n 학교코드', '학교명', '졸업자.2', '(특수목적고)과학고 진학자.2', '(특수목적고)외고ㆍ국제고 진학자.2']
df_1 = df[sel_col]
df_1.columns = ['reg', 'code', 'name', 'grads', 'sci', 'intl']
# 컬럼의 찌꺼지 삭제하기
df_1=df_1.drop(0)
# index
# 보통의 경유 번호로 많이 함
# 시계열 데이터인 경우 인덱스 시간 형식으로 세팅
# values
# 1. 결측 데이터(NaN) 처리
# 2. 데이터 타입 체크
# 결측데이터 집계
df_1.isna().sum()
# reg 2
# code 0
# name 0
# grads 34
# sci 34
# intl 34
# dtype: int64
# 필터링
df_1[df_1['reg'].isna()]
df_2=df_1.dropna()
# 데이터 타입체크 (dtype)
# int => int32, int64
# float => float32, float64
# => datetime
# object(나머지)
df_2['grads'] = pd.to_numeric(df_2['grads'])
df_2['sci'] = pd.to_numeric(df_2['sci'])
df_2['intl'] = pd.to_numeric(df_2['intl'])
df_2.dtypes
# reg object
# code object
# name object
# grads int64
# sci int64
# intl int64
# dtype: object
df_5 = df_2.reset_index(drop=True)
# df의 주요기능들
# 시리즈의 연산, 필터링, apply, groupby, pivot
# 시리즈의 연산
df_5['spc'] = df_5['sci'] + df_5['intl']
df_5['spc_ratio'] = (df_5['spc'] / df_5['grads'] *100).round(2)
# 특목고 진학율 높은 top 50
df_5.sort_values('spc_ratio', ascending=False)[:20]
# 졸업생 100명 이상인 학교 중 특목고 진학율 top 20
df_6 = df_5[df_5['grads']>=100]
df_6.sort_values('spc_ratio', ascending=False).head(20)
# 과고 외고 진학자가 최소 1명 이상인 학교중 특목고 진학율 top20
cond1 = df_5['sci']>=1
cond2 = df_5['intl']>=1
temp = df_5[cond1 & cond2]
temp.sort_values('spc_ratio', ascending=False).head(20)
test = '서울특별시 노원구'
test.split(' ')
# ['서울특별시', '노원구']
def get_sido(x):
return x.split(' ')[0]
# apply
# 한열에 모든 데이터에게 똑같은 코드를 적용
df_5['sido'] = df_5['reg'].apply(get_sido)
df_5[df_5['sido'] == '서울특별시'].sort_values('spc_ratio', ascending=False).head(20)
# 집계 - 여러개의 데이터를 하나의 숫자나 문자로 축약해서 봄
# mean, sum, max, min
df_5.mean(numeric_only = True)
titanic_df.groupby(['sex', 'pclass', 'embarked'])['survived'].mean()
# alone
# False 0.505650
# True 0.303538
# Name: survived, dtype: float64
# pivot
# 카테고리별로 2차원으로 묶어서 집계
pd.pivot_table(titanic_df,
columns='pclass',
index='sex',
values='survived',
aggfunc='mean', margins=True)
import matplotlib.pyplot as plt
# 그래프 크기 설정
plt.figure(figsize=(8, 5))
# 첫 번째 데이터 시리즈
plt.plot([2, 1, 4, 2, 5, 1], marker='o', color='skyblue', label='Series 1', linewidth=2)
# 두 번째 데이터 시리즈
plt.plot([2, 5, 7, 2, 4, 1], marker='s', color='salmon', label='Series 2', linewidth=2)
# 그래프 제목 및 축 레이블 설정
plt.title('Stylized Line Plot', fontsize=16)
plt.xlabel('X-axis', fontsize=12)
plt.ylabel('Y-axis', fontsize=12)
# 그리드 추가
plt.grid(True, linestyle='--', alpha=0.7)
# 범례 추가
plt.legend(title='Data Series', fontsize=10)
# 그래프 여백 조정
plt.tight_layout()
# 그래프 보여주기
plt.show()
## 시각화의 목적
# 남들에게 분석결과 공유
# 스스로 데이터를 이해하기 위해서 (데이터를 보기위한 현미경)
# 데이터 타입에 따라 적절한 시각화 정리
# 데이터 타입 => 카테고리 데이터, 연속된 숫자 데이터
## 1. 연속된 숫자 데이터
# 분포 -> 데이터가 어디에 몰려있고, 어디에 퍼져있는지 살펴보기
# 히스토그램
# plt.hist, sns.histplot
df_5['sido'].unique()
big_city = ['서울특별시', '부산광역시', '대구광역시', '인천광역시', '광주광역시', '대전광역시', '울산광역시', '경기도']
def is_bigcidty(x):
if x in big_city:
return 'bigcity'
else:
return 'smallcity'
df_5['is_bigcity'] = df_5['sido'].apply(is_bigcidty)
### 카테고리 데이터
# 카테고리 별 데이터의 갯수
plt.figure(figsize=(12,3))
sns.countplot(df_5, x='sido')
plt.xticks(rotation=90)
plt.show()
##3. 카테고리 데이터와 숫자 데이터간의 비교
# 카테고리 별 숫자 데이터의 분포
# sns의 boxplot, violinplot
plt.figure()
sns.violinplot(titanic_df, x='pclass', y='fare', hue = 'sex')
plt.show()
# 머신러닝
# 사이킷런 : 머신러닝 모듈
iris_df = sns.load_dataset('iris')
plt.figure()
sns.pairplot(iris_df, hue='species')
plt.show()
- KNN(K Nearest Neighbors)
- neighbors ⇒ 거리
- 새로운 데이터 / 기존 데이터와 거리를 계산
- 거리가 짧은 n개를 살펴봄
- 이 데이터들의 target을 살펴보고 다수결
- Scikit learn 사용법
- 모델을 생성
- 모델을 훈련
- 예측, 검정
from sklearn.neighbors import KNeighborsClassifier
# 1. 모델을 생성
knn = KNeighborsClassifier()
# 2. 모델을 훈련
# feature와 target을 분리
# target은 무조건 1차원
# feature는 무조건 2차원
y = iris_df['species']
X = iris_df.iloc[ : , : -1 ]
knn.fit(X, y)
# 3. 예측, 검정
knn.predict([[5.0, 3.3, 1.45, 0.15]])
# 훈련용 데이터와 검증용 데이터로 나누기
# 8대 2로 나누기
# 섞어서 나눠야 함.(그럴줄알고 사이킷 런은 다 준비해놨어)
from sklearn.model_selection import train_test_split
train_x, valid_x, train_y, valid_y = train_test_split(X, y,
test_size=0.2,
random_state=77,
stratify=y) # random_state : 재현성(맞춰주기)
# 1. 모델을 생성
knn = KNeighborsClassifier()
# 2. 모델을 훈련(fit)
knn.fit(train_x, train_y)
# 3. 예측, 검증(socre)
knn.predict(valid_x) == valid_y # 1
knn.score(valid_x, valid_y) # 2
# 1. 하이퍼 파라미터 세팅
# 2. 모델을 생성
# 3. 모델을 훈련
# 4. 예측, 검증
# 교차 검증 => 적은 데이터를 n등분을 해서 그 중 에서 훈련 검증을 교차로 하는 것
# 마지막으로 평균내고 합친 것 모든데이터 훈련 / 모든 데이터 검증
from sklearn.model_selection import cross_val_score
knn_1 = KNeighborsClassifier(n_neighbors=1)
cross_val_score(knn_1, train_x, train_y, cv=4).mean()
knn_5 = KNeighborsClassifier(n_neighbors=5)
cross_val_score(knn_5, train_x, train_y, cv=4).mean()
# 0.94166666666666666667
- 요령이 있음. 어렴풋이 골라야함. 정확히 딱 정해지지가 않음
- k가 1일때, 주변에 1개 데이터만 보는 것 ⇒ 새로운 예측값이 위치가 살짝만 바뀌어도 불안정함(오버피팅)
- 반대로 k를 무한대로 설정한다면 ⇒ 그냥 제일 많은 빈도의 데이터를 예측값으로 줌(⇒ 평균값으로 예측하는 것 뿐임)
- 하이퍼 파라미터는 오버와 언더피팅 그사이에 적절한 선을 찾는 것
- 어떻게 찾을 것이냐?
- 변곡점 찾기, 이 값을 정확히 찾는 것은 불가능함
- 여러가지 데이터를 넣어서 올라가다 떨어지는 부분을 찾는거임
# 1~30까지 바꿔가며 교차검증을 해보자
score_list = []
for k in range(1, 31):
knn = KNeighborsClassifier(n_neighbors = k)
score = cross_val_score(knn, train_x, train_y, cv=4).mean()
score_list.append(score)
plt.figure()
plt.plot(range(1, 31), score_list)
plt.show()
# iris_df 데이터가 좋은이유? 거리로 계산할라면 => 거리여야함
# 이거는 이미 다 스케일링도 되어있고, 숫자로 되어있음. bias가 일어날 수가 없다.
iris_df['sepal_length'] = iris_df['sepal_length'] * 1000
- 카테고리 형 데이터 → 수치형 데이터 → 스케일링
- feature engineering(가장 중요)
- 하이퍼 파라미터 세팅
- 모델을 생성
- 모델을 훈련
- 예측, 검증
'DI(Digital Innovation) > HYUNDAI NGV in Data Analysis' 카테고리의 다른 글
| 주야경독(feat. HDAT 2) (2) | 2024.11.05 |
|---|---|
| [NGV & KAP 데이터 분석 in 모빌리티] 4주차 (0) | 2024.08.07 |
| [NGV & KAP 데이터 분석 in 모빌리티] 3주차 (0) | 2024.08.07 |
| [NGV & KAP 데이터 분석 in 모빌리티] 2주차 (1) | 2024.08.01 |
| [NGV & KAP 데이터 분석 in 모빌리티] 1주차 (1) | 2024.07.22 |